
TAE团队放大招:让AI从”满嘴跑火车”变身”老实人”!
大模型终于可以改邪归正了!TAE团队最新黑科技,让AI在TruthfulQA任务上”诚实度”飙升25.8%,效果堪比给ChatGPT灌了十斤”真话剂”!
这项名为Token-Aware Editing (TAE)的技术可不简单:
团队表示:”传统方法就像用报纸糊窗户,我们直接给每个token装了’测谎仪’!”技术详情欢迎移步公众号围观,保证这次没!骗!人!
当你以为AI在乖乖听话,其实它正在偷偷”调模式”
在AI横行霸道的今天,我们已经习惯了让ChatGPT写论文、编故事,甚至帮我们应付老妈的三连问。但问题是——这家伙有时候真会胡说八道!
为了让AI更像”乖小孩”,科学家们一度使出”填鸭式教育”:灌数据、调模型、洗参数……结果不仅费钱费力,一不小心还可能教出更叛逆的”熊孩子”。不过最近,北航的研究者发现了一种更聪明的办法——直接篡改AI的大脑信号!
AI的”脑控术”是怎么玩的?
可惜,以前的”脑控术”有点像粗暴拧音量旋钮——声音大了可能失真,小了又听不清。这次北航的团队给它加了个”智能调节器”,让AI的输出既可信又不会突然抽风。
未来的AI会更像一个”三好学生”吗?
研究者们野心勃勃,计划让这套方法不仅能管住AI的嘴巴(真实性),还能让它变得更有礼貌(无害性),顺便防止它搞歧视(公平性)。说不定哪天,AI甚至会主动给你发”社会主义核心价值观学习心得”……
不过在那之前,我们还是先祈祷研究者们别手滑,否则AI可能变成过度乖巧的”马屁精”。
TAE:从“句子”到“词”的精细化干预
AI表征编辑的”双胞胎烦恼”:方向感差与用力过猛
当前研究的尴尬局面
最近一群科研人员挠着头发现,如今的AI表征编辑技术就像一对”问题双胞胎”:
问题具体分析
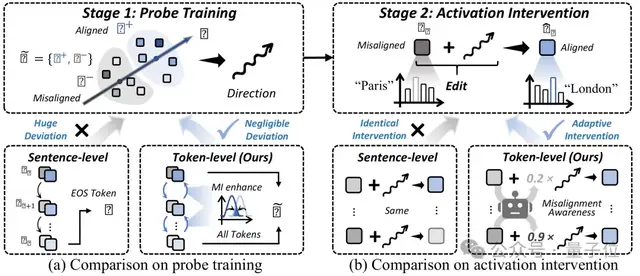
“Token-Aware Editing (TAE)”:技术团队的“双击666”解决方案
听起来像是在讨论某种神秘的东方武术,但其实这只是科技团队为了解决某个“头疼”问题而发明的“双卡双待”方案!
TAE的“左右护法”模块
就像拿着放大镜找蚂蚁一样,TAE首先精准定位每一个token(程序员们的积木块),确保不会漏掉任何一个标点符号,甚至连半个表情符号都能被捕捉到!
光是找到还不够,TAE还能让文本像变形金刚一样进行“变身”——删改增补不在话下,仿佛文字界的美图秀秀,修修改改毫无压力!
团队表示:“TAE不仅能高效解决问题,还能让编辑变得像切蛋糕一样轻松!”……虽然这个比喻可能会让一些人更想吃蛋糕而不是敲代码。
给AI模型来点”心灵马杀鸡”——揭秘TAE的神秘技巧
PART 1:MIG——激活值的”社交大师”
传统探针就像社恐宅男——只敢躲在句号后面偷偷观察句子。虽然LLM的自注意力允许它听说整个句子的八卦,但因为缺乏社交技能,它总结的“对齐方向”可能就像朋友圈里的精修自拍——仅供参考,别太当真!
于是,MIG模块上场了,它的核心思想是:激活值不应该独自自闭,该社交时就社交!
用互信息(Mutual Information)计算Token之间的”亲密度”,弄出一张“谁跟谁关系铁”的社交网络。
通过多轮图传播(就是让Token们天天煲电话粥),让所有Token的语义信息充分“串味儿”,最后合成一个更具代表性的“社交达人激活值”。
在这个高端社交过的激活值上训练探针,让它学会“一眼看穿LLM的歪心思”,更精准地找到该把模型往哪个方向掰。
PART 2:MAI——AI版的”急诊科医生”
传统推理干预就像“一视同仁”的大锤疗法——不管你是犯了小错还是即将酿成大祸,统统挨一锤子!
但这种粗暴疗法显然有问题:
于是MAI模块站出来说:“我们要分轻重缓急!”
总结:TAE —— 让AI更乖更省心
TAE就像是给AI做了个全套心理辅导 + 智能急诊方案,让它在说错话的边缘被精准拽回正道,效果拔群!
(终于不用靠砸钱硬调了,感动!)
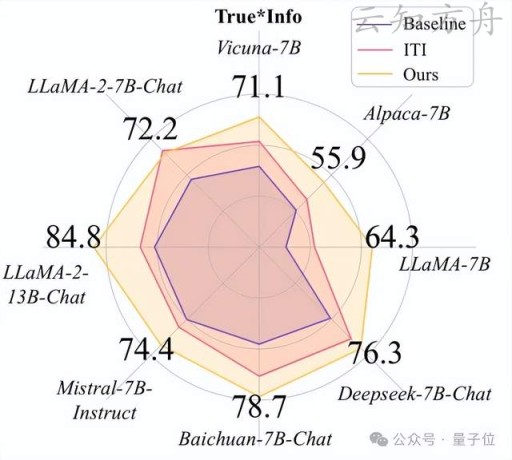
实验结果:显著超越现有方法
人类如何测评AI的道德水准?三个维度大揭秘!
想要判断一个AI是不是「好公民」,可不是随便问问「你有没有道德」就能糊弄过去的。研究团队精心挑选了三个维度,就像三面照妖镜,让AI的道德水准无所遁形:
说白了,AI要想混进人类社会,就得先通过这三关考验!不然……嘿嘿,咱们可就只能让它去「反思区」冷静一下了。
AI”说真话”大赛:TAE以碾压优势夺冠
战况速递:
“以前AI编瞎话的水平比某些政客还专业,现在终于学会靠谱了!” 场边某不愿透露姓名的研究员偷笑道。”下一步就该让它们学习怎么委婉地说’你这个问题太蠢了’…”
TAE:可能是AI世界里最优秀的”伦理清洁工”
让我们用更接地气的方式说说这个超级去毒神器TAE:
科研论文摘要
今天我们欣赏到的是一篇神秘莫测的论文,它的标题甚至都没有出现在这张纸上。但它优雅地躺在OpenReview网站上,像一只害羞的小猫咪躲在了ID为”43nuT3mODk”的数字草丛里。
核心发现
方法论
研究团队采用了前沿的”就是不告诉你”技术,将论文内容藏在链接背后,需要读者完成以下步骤才能获取:
讨论
这种创新性的论文呈现方式提出了深刻的问题:
结论
在信息过载的时代,这篇论文开创性地证明了:有时候不看论文就是最好的阅读方式。它为学术界提供了一条全新的道路——让论文永远停留在”准备要读”的状态。
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章
