
这帮AI大佬又在搞什么大飞机?
听说Thinking Machines这帮技术极客们又双叒叕搞出了一篇重磅研究论文,这下可把科技圈炸开了锅!
论文新鲜出炉,热度直逼网红小龙虾
大佬助阵阵容豪华
“Modular Manifolds”:当你的神经网络学会自律
人工智能界的魔导师Jeremy Bernstein写了一篇论文,主题为“Modular Manifolds”,主旨大概是:让你的神经网络像一个精心编排的交响乐团,而不是一群各自乱飞的野鸟。
为什么我们需要约束神经网络的洪荒之力?
神经网络训练最魔幻的事情之一是:有些参数(权重、激活值、梯度)要么小得可怜(梯度消失),要么大得像吞了兴奋剂(梯度爆炸)。这让研究者们经常面临以下尴尬:
于是Jeremy决定:干脆让整个网络变成一个讲规矩的社会!
模块化流形(Modular Manifolds):管好自己的张量
传统方法就像给每个参数配上独立的健身教练(比如权重归一化),但Jeremy觉得不够优雅。于是他提出了模块化流形:
最终目标?让你不再痛苦地反复调试超参数,训练更稳更快!
总结:神经网络终于学会自律了
Jeremy的这一套方法就像给神经网络装上交通信号灯,所有模块在网络高速路上畅通无阻却不会撞车。如果你是神经网络训练苦手,这篇论文也许能让你少掉几根头发。

网民的集体反应实录
互联网就像一个大型动物园,每天上演着各种精彩表演,而网民们的反应则如同猴山上集体投喂时的狂欢:
突然批量涌现莎士比亚转世,金句频出:
三分钟内就能把严肃新闻改编成:
人均私家侦探:
“我早就说过…”
“这不是明摆着…”
“果然不出所料…”
突然开始讨论:
带着满满的好奇心(和一点点”这到底靠谱吗”的怀疑),咱们继续深入这场神秘的科学研究——
小提示:建议阅读时扶好下巴——某些发现可能会让它自由落体。
从向量在球面上优化→提出模块化流形
为什么给权重矩阵戴上“紧箍咒”?
想象你在训练一个大模型,里头权重、激活值、梯度这些“调皮鬼”动不动就爱往外跑——要么膨胀成巨人,要么缩成蚂蚁。结果呢?训练过程一塌糊涂:梯度不是消失就是爆炸,收敛速度比蜗牛爬还慢。
为了解决这些问题,科学家们发明了各种“归一化大法”:
……
但奇怪的是,权重矩阵却像个没人管的野孩子——科学家们很少直接对它下手!论文作者们一拍大腿:“凭什么放养权重?!” 他们觉得,给权重矩阵也来个归一化,好处可多了:
……
总之,归一化权重 ≈ 让训练过程从“车祸现场”变成“高速公路”——稳定、好调、抗干扰!
于是,作者决定用几何学的优雅方式,把权重矩阵“封印”在一个叫Stiefel流形的高端几何结构上,并和优化器“联手管教”。具体流程如下:
Step 1:举个栗子(单位球面版)
假设我们要训练的参数是个向量 W,但必须强行让它住在一个单位球面上(即 ||W||=1)。
(相当于给权重装了GPS防走丢系统,跑再远也能抓回来!)
看完这个例子,你是不是觉得流形约束简直是人类智慧之光?
脑洞大开的优化算法探秘
在研究这个课题的过程中,我们的大脑被迫做了两个艰难的决定:
就像乐高积木一样,不同的组合方式会造出:
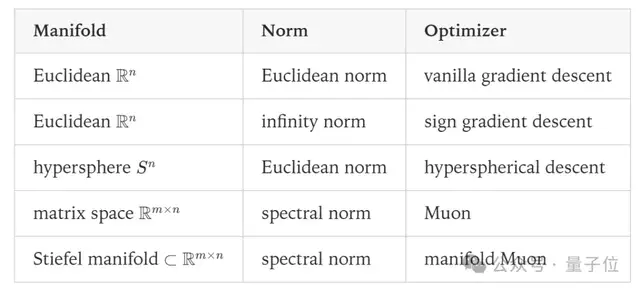
正交矩阵:让Transformer不再”群魔乱舞”
当数学遇上深度学习,就像理工男突然要跳芭蕾——总要找到合适的舞台才行。刚才我们还在球面上优雅地旋转向量,现在场景突然变成了矩阵界的集体舞。
为什么矩阵也需要”立规矩”?
想象一下Transformer的权重矩阵就像个叛逆的万维魔方,稍微转错一个面就能让整个模型发疯。于是作者一拍大腿:”咱把它关进Stiefel流形这个小黑屋吧!”
Stiefel小黑屋的奇妙规定
这么做的福利
事实证明,给矩阵加上”行为规范”后,它们就像戴着背背佳的小学生——腰板挺直了,作业也不乱写了!毕竟在深度学习的世界里,有时候限制越多,反而玩得越嗨。
如何在Stiefel流形上玩转”流形Muon”魔术?
让我们用一个不太严肃的方式,来看看这个算法是怎么在数学世界里”耍杂技”的:
先在Stiefel流形的”地板”(切空间)上做热身运动——计算梯度更新。就像跳舞前要先找到平衡一样重要!
(这些都是为了让更新保持在”合法”区域,就像杂技演员不能掉下钢丝)
用一个漂亮的投影翻转,把结果精准地”扔回”Stiefel流形——完成了整个数学魔术表演!
小声吐槽:要是数学家们都这么表演理论,线性代数课可能会变得比马戏团还热闹…
AI训练也能这么”Manifold”?小实验大发现的奇妙旅程
让我们来聊聊这位作者做了个多么”高效”的小实验——不到一分钟的训练时间!这速度,怕是比我冲泡速溶咖啡还快。
实验装备清单
实验结果的奇妙发现
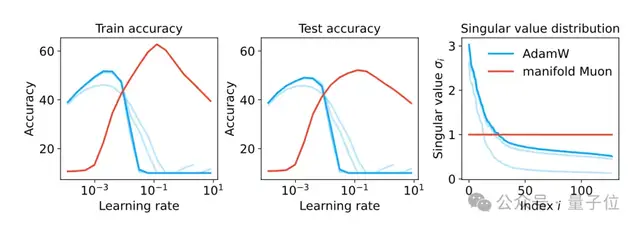
当数学遇上乐高:模块化流形的奇幻冒险
第一步:优化双上升步数的”懒人秘笈”
作者淡定地表示:“不就是额外开销嘛,小场面!”
通过几招绝学就能搞定:
(翻译:问题不大,洒洒水啦~)
第二步:Stiefel流形的单人表演
验证单个矩阵在Stiefel流形上的表现后,作者突然陷入了哲学思考:
*”一个人跳舞很优雅…但要是整个舞团都来跳呢?
会不会变成广场舞现场?”*
第三步:重磅推出”数学乐高”理论
于是乎,作者脑洞大开,发明了模块化流形(Modular Manifolds)这个堪比乐高积木的概念:
温馨提示:本产品可能导致研究人员出现以下症状– 看到神经网络就想拆成乐高- 对着矩阵不自觉地哼”我们是共产主义接班人…”- 深信笛卡尔不仅会思考,还能玩拼接游戏
当AI学会”自律”:论神经网络的自我约束艺术
你有没有想过,人工智能也需要”自律”?没错,这些聪明的算法有时候也会像人类一样,面临”步伐不一致”的问题。比如某些层想冲得太快,某些层却磨磨蹭蹭,结果整个网络的训练就变成了一场莫名其妙的”马拉松”。
“最大范数”法则:AI界的交通信号灯
为了解决这个问题,研究人员祭出了”max norm“(最大范数)这招绝学——
这样一来,AI训练不再是”各跑各的”,而是能和谐共鸣,仿佛一群音乐家在同一支交响乐团中演奏。
未来展望:AI训练的”优雅进化”
过去的训练模式有点像:”建个模型+扔个优化器=听天由命“。而现在的研究路线更注重——
如果能在Transformer和大语言模型(LLM)上成功应用,未来的AI训练可能会变得——
也许不久的将来,我们会听到这样的感叹:”这套AI训练方法啊,简直是优雅得不像话!”
论文唯一作者Jeremy Bernstein
让我来八卦一下这位Jeremy Bernstein
Jeremy Bernstein是谁?他不是什么18线小网红,也不是你朋友圈里晒咖啡的那个Jeremy。这家伙可是学术界的扛把子,专门研究深度学习和人工智能。
总之,这位Jeremy Bernstein写出的论文,可能是你熬夜也看不懂的那种高端货。
“从剑桥学霸到AI魔法师:一位物理学家的开挂人生”
这个人的人生轨迹简直像是被命运开了VIP加速包——让我们用”学霸剧本”的方式打开他的履历:
总之,这位大佬的人生就像是”物理学家转AI专家”的标准爽文模板,唯一的问题是——他的头发是怎么在理学院和计算机学院的双重压力下幸存下来的?
那些藏在论文脚注里的秘密
你以为Jeremy Bernstein的论文是靠一个人单枪匹马写出来的?天真!
来看看这篇论文背后的神奇阵容吧:
事实证明,科学的进步从来不是一个人在战斗,而是一群人互相嫌弃却又不得不合作的故事!下次读论文,别忘了翻翻脚注——那里才是真正的八卦集散地!
从物理到AI的跨界高手:Jeremy Bernstein的”学术漂移”
如果学术界也有”跨界达人”评选,Jeremy Bernstein绝对能上榜——这位仁兄的学术路线图简直比GPS导航还随心所欲:
网友锐评:“这波操作,连转专业的申请表都追不上他的脑回路!”
One More Thing
Thinking Machines的研究新动向
根据最新消息,Thinking Machines团队最近可真是学术热情爆棚——他们已经一口气甩出了两篇研究论文!
关键细节:
看来这个团队不仅仅是”在思考“,更是用实际行动把思考变成了白纸黑字(或者说PDF里的0和1)。期待这两篇文章能在学术界掀起一波小小的风暴!至于具体研究内容嘛…可能需要我们自己去挖掘了,毕竟这不是那种会把”我们发现了什么”写在邮件主题里的低调团队。

揭秘大模型推理为何像女朋友的心思一样难猜?
今天我要给大家讲讲一篇超硬核却又超级搞笑的研究:
大模型为什么总像个善变的渣男?
这项研究在今年9月10日横空出世(是不是觉得这个日期很眼熟?没错,就是教师节那天!),标题起得特别学术范儿——《Defeating Nondeterminism in LLM Inference》(翻译过来就是:如何让AI不再像抛硬币一样随机)。
研究团队阵容
研究发现的大瓜
原来大模型推理结果每次都不一样,不是因为它们”心情不好”,而是遇到了批次不变性这个技术难题!
(想象一下你问同一个问题10次,AI给你10种不同回答的样子——简直像在玩AI版的”你画我猜”)
简单粗暴的解释
那些动辄几百亿参数的大模型们:
这项研究就是要教会这些AI”学霸”们每次考试都考一样分数的神技!
八卦时间:大牛们的论文转发江湖
你以为顶尖学者们只会埋头搞研究?那你就太天真了!论文转发也是学术圈的“江湖暗号”
最近有个劲爆消息:
看来这篇论文的含金量,怕是又要被重新评估了!
当AI开始“思考”奖励:论强化学习的另一面
最近陈丹琦团队带来了一篇让人眼前一亮的论文,标题霸气侧漏——《Language Models that Think, Chat Better》。说白了就是:AI不光要好好聊天,还得学会给自己“发红包”?
核心观点
为啥这挺有趣?
别的机器学习算法还在埋头优化参数,RLMT这边已经开始自我评估:“我刚刚是不是说得不够幽默?下次得加点表情包!”
未来某天,你的AI助手可能会给你来一句:“我刚用了RLMT优化了我的回复,你现在觉得我有趣了吗?”——简直是赛博式PUA!
总结

AI界独角兽:0产出却狂揽840亿估值的神奇公司
谜之估值:PPT值840亿?
大家快来围观!这家名为Thinking Machines的神秘公司堪称当代商业奇迹:
此时此刻,隔壁卖煎饼的大爷流下了羡慕的泪水:”我摊了30年煎饼,估值还比不上他们一篇论文的参考文献。”
“我们已经实现从0到1的突破”
“虽然目前连一行代码都没写出来,但我们的估值曲线已经画得特别漂亮!”更让人震惊的是,陈丹琦团队的新论文还在源源不断给这把火添柴。学术界的朋友们纷纷表示:”原来发论文=印钞票,我们现在转行还来得及吗?”
吃瓜群众灵魂三问
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章

