
腾讯混元放大招:80B参数的”像素魔法师”来了!
听说没?腾讯混元这个科技圈的”魔术师”,这次直接从帽子里变出了一只80亿参数的”像素巨兽”——HunyuanImage 3.0!这家伙可比你家楼下打印店的打印机厉害多了,人家是目前开源界的生图天花板!
这个生图模型为啥这么牛?
它能干啥?
想象一下:
好消息是,这个AI魔法棒现在开源了!再也不用眼馋那些闭源的”小气鬼”模型啦~
(小声说:现在的AI真是越来越不像话了,连画画这种人类最后的尊严都要抢!)
数学也能这么好玩?HunyuanImage 3.0解题太溜了!
各位看官注意啦!今天我给大家表演一个“AI解方程”的神奇魔术~
AI数学老师的show time
HunyuanImage 3.0这位”数字天才”最近又升级了!它不仅是个艺术生,还拿了数学竞赛金奖!
为啥它能这么牛?
最绝的是,它不仅给出了标准答案,还能把解题过程可视化得像教科书一样标准!这让高中数学老师们情何以堪啊~
各位想不想看看这位AI数学老师的手笔?保证让你惊呼:”我的方程从来没有这么好看过!”
当堆排序遇上小黄脸:一场数值的欢乐派对!
堆排序可视化:表情包的逆袭!
想象一下,如果数组里的数字都有自己的“心情”,数值越大越开心,堆排序就像在举办一场表情包狂欢节!我们用小黄脸表情包来代表数字,数值越大,笑脸越灿烂!
堆排序流程
伪代码:手帐风
plaintext
堆排序(HeapSort):
伪代码:
function heapSort(arr):
n = arr长度
// 建堆
for i from (n/2 – 1) down to 0:
heapify(arr, n, i)
// 开始排序
for i from (n-1) down to 0:
交换 arr[0] 和 arr[i] // 把最开心的放最后
heapify(arr, i, 0) // 重新调整堆
function heapify(arr, n, i):
largest = i // 当前最开心的
left = 2*i + 1 // 左孩子
right = 2*i + 2 // 右孩子
// 左孩子更开心?
if left arr[largest]:
largest = left
// 右孩子甚至更开心?
if right arr[largest]:
largest = right
// 如果有人比当前最开心的还开心,就换位!
if largest != i:
交换 arr[i] 和 arr[largest]
heapify(arr, n, largest) // 继续检查下面的孩子
小红书风总结
堆排序,就是一场表情包的快乐接力!
最大的数字笑到模糊,站到顶端!
每次选出最开心的一个,让它去队尾休息!
剩下的数字继续PK,直到全都排好队!
画小黄脸时,数值越大,嘴巴咧得越开!
堆的形状像一颗倒着的树,快乐从顶部传递!
每次交换时,可以把“最快乐小黄脸”画个特效!
就这样,一堆混乱的数字,变成了快乐的有序队列!
文字渲染:从“糊一脸”到“糊一脸艺术”的进化论
还记得当年那些像素感人、字体模糊得像被大象踩过的“创意”海报吗?现在,HunyuanOCR带着它的3.0版本强势登场,终于让你的文字不再像超市促销传单!
三大升级,告别“马赛克美学”
效果对比
无论是表情包怼人、海报唬人,还是朋友圈装X,现在通通一键搞定,让你的创意不再被渣画质拖累!
HunyuanImage 3.0:当AI遇上设计师的灵魂碰撞
进化之路:从理工直男到艺术绅士
HunyuanImage 3.0可不是简单迭代的“数字民工”,它在设计师的魔鬼训练下,成功完成了审美的华丽转身——
美学训练:AI界的“变形记”
为了让这位AI同学摆脱“钢铁直男式”审美,团队下了狠手——
最终,HunyuanImage 3.0成功毕业,甚至能对着用户的草图深情朗诵:“您这张……颇有康定斯基早期的神韵。”(尽管原图只是随手涂鸦的土豆)

AI的艺术魔法
这家伙简直就是哆啦A梦的神奇口袋,啥都能掏出来!
(小声说:这么好用,该不会哪天取代人类艺术家吧…瑟瑟发抖.jpg)
听说腾讯家的混元大模型最近正式亮相了,科技圈的小伙伴们纷纷表示:“这年头,大厂不出个AI模型,都不好意思说自己搞技术的!”
总之,技术圈的“神仙打架”又添一员,吃瓜群众已备好小板凳。(手动狗头)
核心技术方案
当AI学会了”心有灵犀”——Hunyuan-A13B的多模态革命
谁说AI不能”一心多用”?最新推出的Hunyuan-A13B就像个学霸里的”多边形战士”,80B的总参数量让它堪比一个装满知识的移动图书馆(不过它真的不会抱怨背书)。最厉害的是,它把文本理解、视觉识别和图像生成这三项绝活都塞进了同一个”大脑”,而且还能无缝切换——
最神奇的是,13B的激活参数量意味着它特别懂得”节能”——只在需要时才点亮相关脑细胞,活像个精通”工作摸鱼平衡术”的职场老手。
这下好了,AI不仅知道你要什么,还能一次性给到位。以后让它画”会跳舞的西兰花”,估计连伴舞的牛排都能自动安排上!
混元3.0:一款不仅能吹牛还能画画的AI
你们还在用传统的DiT路线?那就像拿着大哥大和iPhone 14比谁的屏幕分辨率高一样可笑!混元3.0可不走寻常路,它选择了“大模型就是一切”的王者路线——
核心优势:
总之,混元3.0告诉你:“大模型不仅能写作文,还能画画,以后没准还能给你煮咖啡——只要训练数据足够!”
双编码器结构
AI绘画界的”变形金刚”:混元3.0的那些黑科技
1. 看图说话新境界
混元3.0简直是个”视觉美食家”,先把图像扔进VAE+ViT这对”黄金搭档”里:
然后像吃自助餐一样把视觉特征和文字特征统统摆在同一条传送带上!
2. 画画也能”聊”出来
它的绘画系统简直就是艺术界的”百变星君”:
“老板,这个夕阳要不要再红一点?” —— “好嘞!马上给您PS成火山爆发效果!”
广义因果注意力
当AI开始”看菜下饭”:解读广义因果注意力的神奇之处
你以为AI只是个死板的”计算器”?不不不,现在它学会”看人下菜碟”了!HunyuanImage 3.0带来的广义因果注意力(Generalized Causal Attention),简直就是AI界的”社交达人”,懂得在什么场合该怎么表现——
这就像让一个既能写诗又会画画的才子,在同一时间里——
谁说AI不能”一心二用”?它现在可是真正实现了“左手写代码,右手画大饼”的境界!
想象一下,你的大脑正在玩一场高端的”图像接龙”游戏——
让AI像吃了记忆面包一样,在长篇大论的对话中——
(背后的科学原理:用”图文连连看”的方法治好了AI的健忘症)
二维位置编码
当数学遇上艺术:HunyuanImage 3.0的”像素级”脑回路
你以为AI只是在算数学题?No no no,它其实是在用三角函数跳”位置编码广场舞”!HunyuanImage 3.0这个家伙可不得了:
x轴和y轴的频率参数θ各玩各的,就像夫妻俩各自有工资卡但神奇的是,这套”AA制”编码法还能完美兼容老版的”单身汉”文本编码!最后友情提醒:这不是什么黑魔法,而是AI在小心翼翼地保护自己好不容易学来的”说话本事”,同时偷偷摸摸地解锁”看图说画”新技能!
数据处理流程
大数据过滤器历险记:50亿张图片的逆袭之路
第一阶段:”垃圾堆”大扫除(100亿→75亿)
想象一下,你面前摆着100亿张图片——如果每张都是一片饼干,足够喂饱全银河系的外星人了!但问题是,这些”饼干”里混着:
我们的算法小哥戴着虚拟口罩,挥动代码扫把,一口气清走了25亿张”黑暗料理”。
第二阶段:”颜值即正义”淘汰赛(75亿→60亿)
剩下的图片被送上《图像101》选秀舞台,评委标准包括:
15亿张”海选选手”当场领了盒饭。
终极加强版:知识buff加持(60亿→50亿)
最后我们给数据打了两针”聪明剂”:
最终胜出的50亿张精英图片,现在能优雅地处理:
让AI画出的蒙娜丽莎不会突然眨眼睛
保证搜索结果不会把”柯基犬”显示成”会跑的吐司面包”
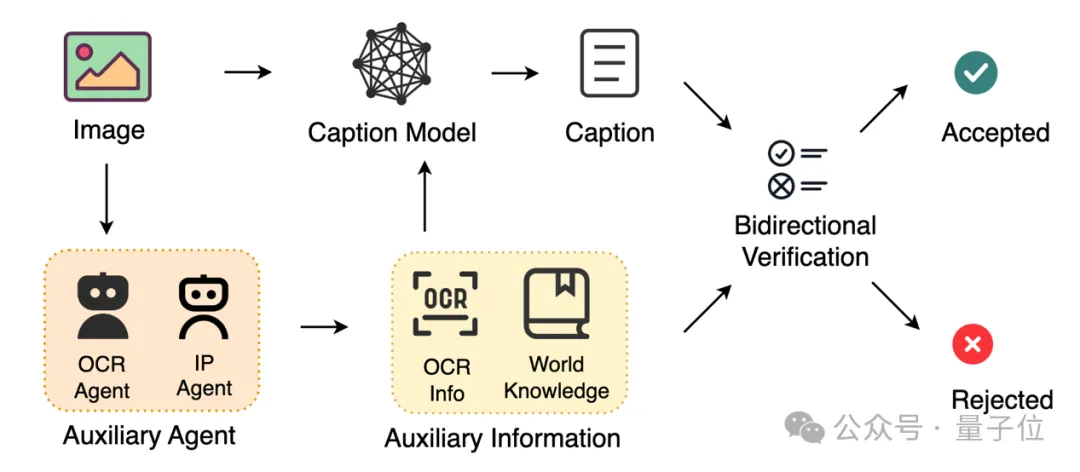
图片描述:一场“语言马戏团”的杂技表演
科研人员最近搞出了一套描述图片的新花样——就像在马戏团里看杂技,不过是文字版的。
分层描述:从“小学生作文”到“大学教授论文”
(适合不想动脑子的你)
“这是一张图,里面有东西。”
(适合假装懂艺术的你)
“这张图的风格介于梵高的癫狂和蒙德里安的强迫症之间。”
(适合福尔摩斯式较真的你)
“图中有一只名叫Tom的猫,正在思考为什么主人宁愿刷手机也不陪它玩。”
动态标题生成:玩转“文字俄罗斯方块”
科学家们发明了一种“组合式合成策略”(其实就是随机拼句子游戏),让AI能像俄罗斯方块一样灵活拼接标题:
OCR和NER:AI的“侦探工具包”
为了让AI不说瞎话,团队给它配了两个小助手:
确保AI不会把“禁止停车”认成“免费烧烤”。
防止AI把“马斯克”认成“一只会发推特的猴子”。
就像你和朋友互相检查对方有没有穿反裤子一样严谨。
差异描述:找不同的高级玩法
AI不仅能看图说话,还能在两张图中找不同:
推理数据集:让AI学会“脑补”
为了不让AI只会死记硬背,科学家们决定训练它“脑补”:
教会AI如何从“天气好热”推理出“我想吃冰棍”。
让AI不仅知道“一只猫在月球上”,还能画出戴着宇航头盔的猫。
让AI能像人类一样先胡思乱想,再动手画画,而不是只会“复制粘贴”。
多阶段训练策略
像素晋级赛:从256到1024的视觉马拉松
你以为AI生图画风突变的秘诀是什么?随机抽卡?不!这是一场精心设计的”分辨率晋级赛”,AI像个被迫报名健身房的新手,从弱不禁风的256像素”小土豆”开始:
吃着最朴素的”图文对照盒饭”,偶尔配点纯文本维生素片,连VAE(视觉增强器)都只能吐出马赛克级别的朦胧美——像极了新手画家颤抖的第一笔。
突然被投喂”高蛋白数据餐”,分辨率翻倍像打了激素。这时候AI开始嘚瑟:”我能画清晰的手指了!”…然后继续画出六根手指的克苏鲁怪物。
教练突然往训练菜单里撒魔鬼椒:多图缝合术、PS级编辑指令,外加”思维链”益智饼干。AI边哭边进化,终于在某个深夜顿悟:”原来甲方要的’五彩斑斓的黑’是这个意思!”
“恭喜你从毕加索抽象派毕业了…现在请开始学习如何正确画一只正常数量的柯基犬尾巴。”
当AI开始”创作学院”进修之旅
阶段一:预训练——疯狂的”知识暴食症”
模型一开始就像个刚上大学的新生,面对海量的多任务数据疯狂摄取知识,企图成为”全能学霸”——从天气预报到莎士比亚,从菜谱到量子力学,统统塞进它那深不见底的”脑回路”。
阶段二:指令微调——变身”甲方快乐机”
这时,模型开始专业化进修。训练数据变成了格式化指令,比如:
目标很简单:让AI学会精准满足人类脑洞,而不是自顾自地搞抽象艺术。
阶段三:后训练——人类的”挑三拣四”大法
最后的精修阶段,人类拿出三套终极武器来调教AI:
AI被迫学会审美,避免产出精神污染。
模型测评效果
HunyuanImage 3.0测评方式的魔幻漂流
测评方式大揭秘
这个图像模型正在接受:
测评趣闻
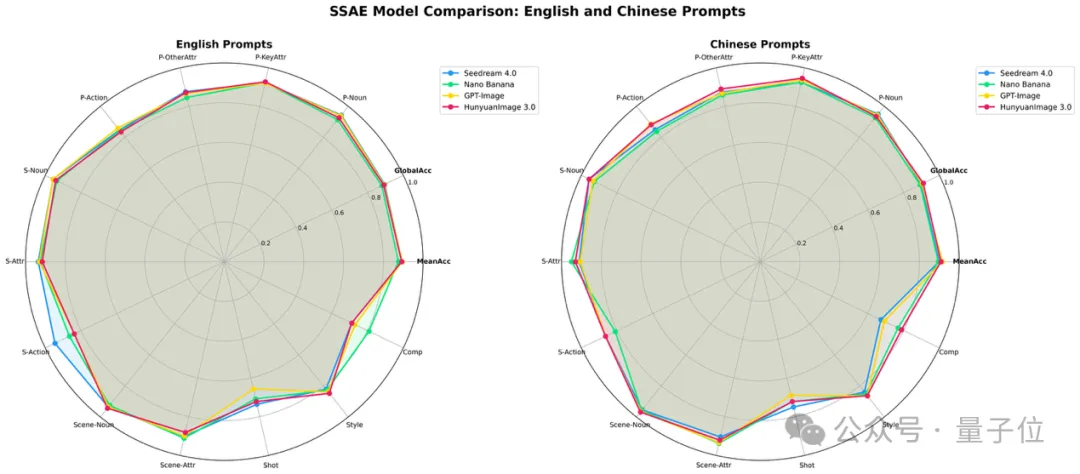
看图说话:SSAE带你看清AI画图的”小心思”
还记得小时候做连线题吗?现在的AI画图也要经历类似的考试了!今天我们要介绍的这位叫SSAE的”考官”,专治各种”文不对图”的AI画师。
SSAE是谁?
简单来说:
这门考试有多严格?
SSAE可不是随便问问”这张图画的是什么”,而是把每道题拆成12个小细节:
…
成绩单怎么看?
每个AI画师都会拿到两张成绩单:
HunyuanImage 3.0:班里的新学霸
就在大家以为Midjourney、DALL·E这些”老学长”已经是天花板时,来自中国的HunyuanImage 3.0同学交出了一份惊人答卷:
看来AI绘画界的”内卷”已经蔓延到考试领域了。下次当你看到AI画出六指琴魔时,就知道SSAE考官一定会给它扣分!
AI模型大乱斗:HunyuanImage 3.0上演逆袭好戏
在最近这场AI图像生成界的华山论剑中,HunyuanImage 3.0可谓是一匹黑马:
结论?HunyuanImage 3.0不仅媲美顶级闭源模型,甚至还可能把它们挤到观众席!
(PS:好奇这个开源战神?自己去GitHub围观吧!)
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。