
华为黑科技:让AI推理速度一路狂飙,连光速都自愧不如!
最近诺亚方舟实验室悄悄搞了个大新闻——他们的最新研究“不牺牲质量,速度直接翻3.2倍”,成功登上AI顶会NeurIPS 2025的舞台。这可不是普通的加速,而是“多模态大模型的极速超车”,连特斯拉看了都想拿来优化自动驾驶!
这项研究有多厉害?
为什么这么牛?
据说他们用了一些“黑魔法”级别的优化技术(具体是啥?论文里见真章),反正就是让模型推理跑得跟闪电侠似的,质量还稳如泰山。
未来应用?
这项技术要是落地,以后可能真的没人敢说AI反应慢了,毕竟——“它比你闪避老板消息的速度还快!”
“视觉感知投机推理”:让AI看图说话不再”卡成PPT”!
长期以来,多模态大模型(VLM)处理图像和语言任务时,推理速度堪比老年机加载高清电影。虽然”投机推理”(Speculative Decoding)技术能在纯文本领域飙车(GPT加速最爱这招),但在视觉语言上却像个新手司机,1.5倍速都够呛。
华为诺亚方舟实验室:”ViSpec”上线,VLM从此学会”飙车”!
他们捣鼓出了一个“视觉感知投机推理”ViSpec,直接把加速比拉到了3.22倍,还丝毫不影响生成质量!(注意:这不是硬件升级,纯纯的算法魔法!)
为什么之前的加速方案不好使?
ViSpec的绝招:轻量级的视觉适配器
华为的解决方案简单粗暴但极其有效——让草稿模型学会看图!它动态筛选视觉关键信息,而不是傻乎乎地处理所有像素点,从而让预判更精准、计算更高效。
未来展望:从PPT播放到4K流畅
ViSpec的成功意味着大模型的视觉推理不再是个速度瓶颈,未来——
VLM用投机推理技术加速有限
多模态大模型的”话说得快不快”之谜
一、大模型的”看图说话”困境
现代大模型的多模态能力仿佛坐上了火箭,蹭蹭蹭往上涨。但它们却遇到了一个堪比”中年发福”的难题——推理速度。
想象一下这个场景:
结果就是:算力爆炸!延迟飙升!这让大模型在需要即时反应的场景(比如在线聊天、智能客服)里表现得像个网卡加载中的表情包。
二、”军师与主公”的投机妙计
为了解决这个问题,科学家们搬出了投机推理这个利器:
“主公!下个词可以写’胖乎乎’、’圆滚滚’或者’营养过剩’!”
“准了,就用第三个方案吧”
这套组合拳在纯文本领域打得虎虎生风,能让生成速度翻着跟头往上涨。
三、当投机推理遇上多模态…垮了
但把同样的方法用在多模态任务上,效果堪比:
数据显示,现有方法在视觉语言模型(VLM)上的加速效果:
学术界和工业界的研究者们挠着头表示:”这届模型,不好带啊!”
问题出在哪?
眼睛一闭一睁,AI提速3倍!华为”火眼金睛”让AI看懂世界
人类VS机器:谁的视力好?
主公和军师:一场AI版的”诸葛亮难当谋士”
想象一下:大型VLM模型就像一位经验丰富的主公,一眼就能看穿图片的核心:”嗯,这显然是在拍午饭”,而小型草稿模型这位军师则对着各种像素点抓耳挠腮:”主公您看这片区域的色彩饱和度与午餐有何关联?要不要先分析3000个参数?”
结果可想而知,主公气得直翻白眼:”否决!否决!再否决!”
ViSpec:给AI戴上神奇眼镜
华为诺亚方舟实验室一拍大腿:”让’军师’也别天天当近视眼了!” 于是他们研发了ViSpec——一套专治AI”视觉障碍”的神奇框架:
技术圈的震撼消息
据悉,这是目前VLM领域最成功的”视力矫正手术”,连研发团队自己都表示:”我们也没想到效果这么夸张!”
现在AI不仅能看懂世界,还能用闪电般的速度看懂世界!说不定下次你刚上传照片,AI就已经把你的午餐分析得清清楚楚:”拒绝讨论第450个像素点,这就是碗牛肉面!”
三大“独门秘籍”,让草稿模型“看”得更准
ViSpec的逆袭之路:三大黑科技揭秘
你以为让小模型处理大图像很简单?天真了!
ViSpec团队微微一笑,掏出了三大黑科技,让草稿模型终于不再是“看图懵圈”的小可怜。
核心创新一:轻量级视觉适配器(又名“瞄一眼就知道你在搞啥”)
让小模型看大图,就像让近视眼站在足球场的一端看清对面球员的球衣号码——太难了!
这不就是个天才操作吗?但这还没完,ViSpec还有剩下两大招数……
ViSpec:让AI看图说话不再”忘词”的神奇法宝
一、图像压缩界的”榨汁机”
想象一下你参加了个”看图写万言书”比赛,面前是1000页的图片资料——这时候ViSpec适配器就派上用场了:
二、防健忘的”视觉GPS”
AI写长文时的典型症状:”开头还记得图片里有只猫,写到第500字就开始描述恐龙了…”
ViSpec的解决方案:
三、数据不够?AI自己生!
遇到”需要长文本数据集”这个难题时,研究团队的脑洞:
总结:ViSpec就像是给AI装了个”看图说话”外挂,既防健忘又省内存,再长的文章也能把图片记得牢牢的——终于不用看到AI把熊猫描述成”会爬树的北极熊”了!
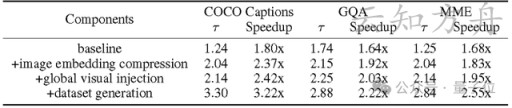
实验结果:性能与效率双丰收,最高3.22倍加速
机器人选美大赛实录:ViSpec的环太平洋之旅
最近AI界举办了一场别开生面的”多模态机器人视力大比拼”。参赛选手阵容堪称豪华:
所有参赛选手都在ViSpec的严格监督下完成了:
这场比赛证明了:就算是AI,也要定期做视力检查!

CV圈的闪电侠:ViSpec让多模态模型起飞了!
性能表现炸裂细节
核心技术解剖
让我们把ViSpec这件”神器”拆开看看:
未来展望:开启VLM高效推理新时代
ViSpec:让视觉模型”开挂”狂奔的黑科技!
听说过”视觉障”吗?就是那些号称能看懂图的多模态大模型,一到现实应用就卡得像老爷车——现在ViSpec给它装上了氮气加速!
ViSpec的三大绝技
未来展望
ViSpec的诞生,标志着VLM从”能用”正式迈入”好用”时代——就像智能手机取代功能机,谁还用慢吞吞的”人工智障”?
(注:论文和技术细节请移步学术平台,这里只负责让你笑着看懂黑科技!)
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章

