科技巨头的艺术天赋?
OpenAI最近用实际行动证明:人工智能再聪明,也不能避免人类的基本失误。
一场视觉灾难的诞生
在GPT-5发布会上,OpenAI成功做到了:
双重踩坑:用一个图表得罪了整个数据可视化界视觉暴力:让比例失调成为了新的艺术流派效率突破:完美演示了从错误到改正的全流程“如果我们的图表错了,那是因为我们想先给大家看错误案例。” —— OpenAI宣传部(我就瞎掰的)
教科书级别的公关危机响应
OpenAI随后用实际行动证明他们有:
超强的纠错能力(花了整个发布会的时间修正一张图表)敏锐的时尚嗅觉(知道比例失调已经不流行了)厚脸皮(这才是最重要的职业素养)正如一位网友精辟总结:”看来AI模型能写出完美代码,但还画不出完美图表。”这大概就是所谓的术业有专攻吧!

GPT-5 VS Claude:一场数据的”魔术秀”
噢,亲爱的观众朋友们!今天我们来看一场人工智能界的最新大戏——”数据打架:谁能把我的图表讲得更离谱“。
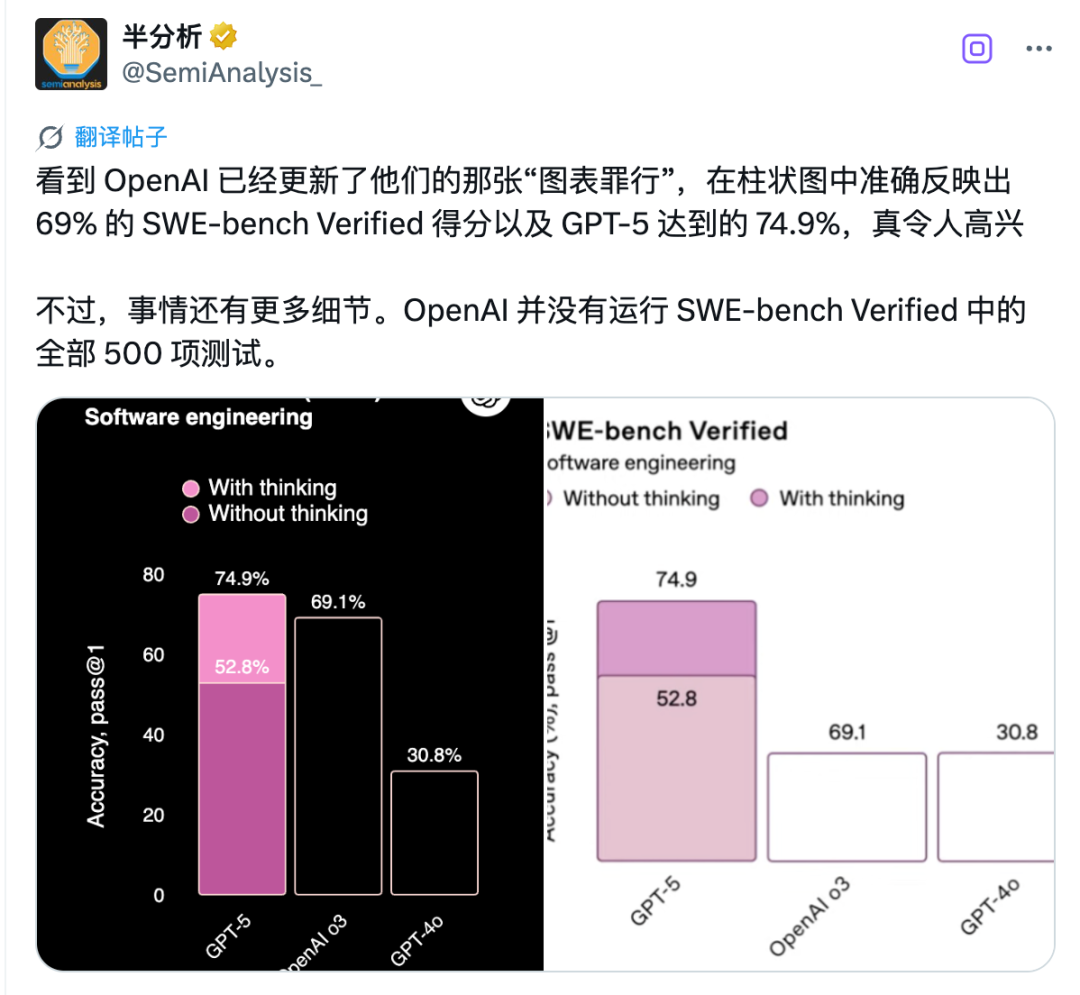
第一幕:官方庆祝烟花秀GPT-5 挥舞着它的”75%高分成绩单”,自信满满地喊道:”瞧瞧我!SWE-bench Verified 74.9%,Claude 你小子这回服不服?”
第二幕:侦探 SemiAnalysis 的放大镜然而,就像所有英雄登场的故事一样,这里需要一位真相挖掘者。SemiAnalysis 戴着”侦探帽”出现了:”慢着,朋友!你的饼图上似乎沾了点猫腻的奶油啊?”
第三幕:幕后花絮之”调参数的艺术”原来,GPT-5 的”高光时刻”可能只是……呃……选择性展示?分析师们搓着手表示:”如果把测试范围稍微扩大一点,这把胜利的火炬恐怕会被泼一盆冷水。”
所以——究竟是GPT-5 真的一骑绝尘,还是有人偷偷给赛车加了氮气?我们不妨拭目以待,看看下一次”AI奥运会”,谁会先掏出他们的黑科技橡皮擦,把数据涂改成自己喜欢的样子!
当AI程序员遇上”BUG考官”:一场代码界的考试大战
左边是新成绩单(像刚拿满分的学霸),右边是旧成绩单*(像交卷前发现笔没水的我)——大家好,欢迎围观这个AI界的”程序员资格考试”!SWE-bench Verified 是什么?
简单来说,这就是个专门为难AI的“代码版五年高考三年模拟”,里面塞了:
500道送命题(严格来说是从GitHub扒来的真实bug)热门Python项目大杂烩(Django、matplotlib、scikit-learn…AI看了都想摔键盘)极致还原社畜日常:AI必须像卑微打工人一样正经提交PR修复bug,还得通过所有测试用例(甲方式微笑)关于”作弊”的小八卦
虽然总有人说AI可能背题库作弊(就像考前偷偷把答案写在橡皮上),但业内还是公认:
这已经是最接近现实版”代码修罗场”的测试毕竟让AI体验被测试用例连环暴击的快乐,可比让它写”Hello World”刺激多了友情提示:下次看到AI修复的PR,建议先检查有没有偷偷谷歌答案(狗头)
企业诚实度的较量:做完整套题和偷偷划题的差别
最近AI界上演了一场有趣的”诚信考试”:
老实孩子Anthropic:8月6日带着Claude Opus 4.1隆重登场老老实实完成了500道全套模拟题最终得分74.5%,但胜在态度端正精明玩家OpenAI:亮出74.9%的漂亮成绩单仔细一看题库发现少做了23道题这算什么?战略性跳题还是题库缩水特供版?这就好比:
一个学生做完全套模拟卷另一个”偶然”跳过最难的23题却还能得意洋洋地说”我平均分高一点”真相往往藏在那些没做的题目里*——谁知道被跳过的是不是特别困难的那些呢?这个AI版的”考试技巧”真是让人会心一笑啊!
当OpenAI开始玩”数学游戏”
数字不会说谎……除非有人选择性展示它们。
一场关于500道题的”精打细算”
SemiAnalysis 小算盘一扒拉:
官方成绩单:74.9%的正确率,500道题考了374.5道题的正确率。小字标注:OpenAI其实只跑了477道题,23道直接“蒸发”。OpenAI的解释:“这些题在我们现有的基础设施上跑不了!”(翻译:机器跑不动,怪我咯?)微妙的”敞亮”与”不敞亮”
敞亮点:至少老实承认跑不了477道题,比起装死强。不爽点:别的AI都在认认真真跑500道题的标准套餐,OpenAI默默砍掉23题,再把分数大喇喇地印在成绩单顶层——仿佛在说:”大家快来看我的优秀成绩!”(选择性展示技能点满)。这不是第一次了!
今年4月,GPT-4.1发布时,OpenAI就玩过这招:
承认事实:同样少做题了。“保守估计”:如果算上那23道”0分题”——成绩从54.6%咣当跌到52.1%。(还是那句话,成绩单放大的时候,小字记得缩到看不见。)结论*:AI领域的技术进步固然值得夸,但算分的魔法还是得透明点,不然观众们不得不怀疑——OpenAI是不是在后台偷偷调整了”数学规则”?
当AI遇到”净化版”考试:一场科技界的趣味辩论
灵魂拷问三连击
题目VS技术:是题库出了”叛徒”,还是AI真的”脑子不够用”?难度玄学:要是23道全是”送命题”,那GPT-5和Claude Opus 4.1的PK岂不是变成了”谁更擅长踩雷大赛”?测试集的身世之谜:这个SWE-bench Verified居然带着OpenAI的家族徽记!OpenAI的”大扫除”行动
2024年,OpenAI的程序员军团发动了一场史无前例的”题库净化运动”:
93名人类监考老师对着1699道题集体”挑刺”奇葩评分标准:0分:”这题我会!”(AI表示毫无压力)1分:”等我百度一下…”(需要场外求助)2分:”你再说一遍?”(题目自带朦胧美)3分:”出题人你出来!”(堪称AI界的哥德巴赫猜想)净化后的”考试精华液”
这群严厉的判官们二话不说:
把2分和3分题统统扔进垃圾桶(像极了学生时代撕掉的错题本)从剩下的”乖宝宝”题目中随机抽取500道隆重推出SWE-bench Verified——一款去除了”超纲题”的AI特供测试现在你知道为什么有些AI突然”学霸附体”了吧?毕竟考题都是提前排练过的”真题模拟”啊!
当AI既当裁判又当运动员时…
想象一下:你的竞争对手不仅和你一起参加比赛,还负责制定比赛规则!这就是OpenAI目前的”神奇”处境——他们就像那个既烤蛋糕又当评委的美食博主,最后还得给自己颁发”最佳烘焙师奖”。
为什么swebench.com更靠谱?
原汁原味测试:就像一个不用美颜相机的直男自拍——最真实的AI水平暴露无遗。工具限制:只能使用bash命令行,就像只给你一把瑞士军刀去参加野外生存挑战。公开透明:测试框架像玻璃厕所一样毫无隐私——所有人都能看到里面在发生什么。结论*:下次看AI比赛成绩单时,记得先看看裁判是不是也在选手名单上!(就像让狐狸负责设计鸡舍的安全系统…)
AI竞赛风云:Claude 4与GPT-5的爱恨情仇
AI界最近上演了一出精彩大戏*:Claude 4 Opus在5月14日的榜单上,像一个偷吃零食的优等生,偷偷摸摸地超过了GPT-5OpenAI则表示:”家人们谁懂啊,我们还没认真呢”,随即祭出了他们的”秘密武器”OpenAI的”钞能力”表演
他们的内部推理模型在国际信息学奥林匹克竞赛(IOI 2025)上:
AI组冠军人类总排名第6最重要的是——同一个模型之前还拿了IMO金牌,这次根本没专门训练就来参赛了比赛详情相当刺激*: 仅用5小时
允许50次提交
不联网的严苛条件下
依然轻轻松松把金牌揣兜里,这推理能力和代码生成水平简直是AI界的”作弊器”
BUT!(重点来了)*这根本就不是你能在ChatGPT里调戏的那个GPT-5,而是OpenAI藏在实验室里的大宝贝:
体积可能更大能力更强烧的钱肯定也更多这就好比你看到邻居家里开着超跑,转头跟你说:”别羡慕,我车库里还有一架直升机呢”* 网友评论*:”所以我们现在用的是GPT-5的’青春版’?” OpenAI笑而不语…
OpenAI 的”营销魔法秀”
看来 OpenAI 的营销团队完全可以开个”如何在考试中优雅作弊”的实战培训课:
SWE-bench 考场奇遇记少做了23道题?不重要!重点是总分要像餐厅评价一样放大显示(悄悄把不及格的试卷塞到桌子底下)IOI 奥林匹克花式操作派出秘密武器”奥特曼特供版”模型轻松斩获金牌后淡定表示:”这只是我们后厨的学徒水平”围观群众自动脑补成:”ChatGPT已经能吊打人类了”这波操作堪称:
考试的艺术家分数的魔术师对比度的操控大师建议下次直接发布《如何用统计图表征服世界》的教程,我一定第一个报名!
AI竞赛:百分点的战争
在这个疯狂内卷的AI时代,连0.42%的差距都能被包装成”颠覆性突破”——是的,你没看错,就是个位数小数点后的那点儿优势。
测试环节的神奇操作*:范围选择:只测晴天不测阴天,AI识图准确率立马飙升50%题目设计:专挑自家AI练过的题型,堪比考试前泄题计分魔法:把”勉强正确”算满分,”基本错误”算半对这哪里是技术竞赛,分明是”大家来找茬”的极限版。当你在新闻里看到”再次刷新SOTA记录”,建议先检查下他们用的是什么显微镜。
科技圈的”性价比大战”,胜负早已注定?
数字游戏还是真香定律?
当科技迷们还在为那2%的性能差距争得面红耳赤时,精明的普通用户早就看穿了一切——*价格!价格!还是价格!*GPT-5的定价策略简直是一场”数学降维打击”:
Opus对比:便宜整整10倍!(这不是买矿泉水,是买AI啊朋友们)Sonnet对比:价格直接腰斩有余!(买一送一的节奏?)网友们纷纷表示:
“吵架不如省钱,2%的理论差距抵不上钱包的真实缩水。”
“性能参数是虚拟的,但信用卡账单是实在的。”
谁是真正的”硬指标”?
在这场科技版的”性价比大战”里,用户钞票的投票权远胜于实验室跑分。毕竟:
极客在乎小数点后的较量普通人只在乎:’它香吗?'”(文章信息来源:微信公众号“APPSO”——那群总能在参数海洋里捞出实用主义的”明日产品猎人”)*总结: 当科技大佬们还在为跑分暗自较劲,消费者早就用脚(和钱包)投了票——便宜大碗,才是永恒的真香!*© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。