多模态大模型的新”看家本领”:当AI开始较真像素级别的细节
从”大概就行”到”分毫不差”
还记得那些早期的多模态大模型吗?它们就像一个粗心的画家,给你画个”大概的猫”,结果可能画出四只耳朵——反正”差不多”是猫就行!但现在,AI学者们已经不满足于这种敷衍了,它们开始研究如何精准到像素级别的图像分割任务。
然而,事情没那么简单。无论是OMG-LLaVA(名字听起来像在喊”OMG!”)还是CVPR 2024提出的LISA(对,就是那个用embedding-as-mask方法的),都存在两大”职业病”:
为什么AI总在这些地方犯傻?
研究人员发现,这些问题主要源于两点:
华科&金山办公的”AI视力矫正方案”
为了解决这些问题,华中科技大学和金山办公的”AI眼科医生”们联手开发了两个核心”矫正镜片”:
1. 语义增强特征提取器(SEFE)
2. 交错局部视觉耦合(ILVC)
最终成果:LIRA——新一代”像素级强迫症”模型
经过这些改进,研究团队推出了LIRA,在分割和理解两项任务上都达到了SOTA(State Of The Art,也就是”目前最牛”的意思)。
现在,AI终于不再把西兰花当树,也不会给猫画六条腿了——至少,没那么离谱了。
你以为现有的AI模型已经很全能了?抱歉,LIRA要来踢馆了!
更厉害的是,LIRA已经成功“出道”——被ICCV 2025录用,看来学术界也挡不住这位“六边形战士”了!
现有方法仍常常无法准确分割目标
人工智能的分割困境:当像素遇上”红白不分”
在多模态大模型的进化历程中,研究者们成功地把视觉理解和像素级分割这两块食材扔进了同一口锅里。结果嘛……有些菜品不错,但也偶尔糊锅。
LISA(CVPR 2024)提了个妙招——”embedding-as-mask”(可以理解为”拿嵌入向量当答案”)。大概意思是,既然AI都在搞语义理解,不如让它顺便做个填空题:”这幅图的分割答案是“。可惜,这招虽然聪明,但AI的回答偶尔会跑偏,比如把大象当成沙发,或者把汽车当成”一块会跑的金属”。
OMG-LLaVA更狠,直接把通用分割模型当成一台X光机,用来扫描图片的”骨骼”,然后把结果和大模型的”理解能力”搅拌在一起。理论上,它能聪明地分割一切;实际上,它可能会指着”红色公交车”说:”这不就是白色汽车的变形版吗?”(参见Figure 2里的翻车现场)。
虽然进展喜人,但当前的分割模型仍然会遇到”最难的一课”:
未来,AI或许会变得更靠谱,但现在嘛……人类的”看到啥就是啥”依然是终极黑科技。
当AI遇上”左边强迫症”:多模态大模型的神秘分割癖好
实验的搞笑发现
研究团队像是拿着一把AI放大镜,在多模态大模型的”大脑”里发现了有趣的现象:
AI的视觉理解为何如此”局限”
这引出了一个灵魂拷问
我们的AI究竟是在理解图像,还是在玩一场高科技的连连看?当模型开始执着于左边的公交车时,是该笑还是该哭?这种”左边强迫症”背后,是不是暗示着多模态理解的某个关键缺口?
也许下次我们应该在训练数据里多加些右边的内容——毕竟世界不是只有左边的公交车值得关注!
同时支持理解和分割任务的多模态大模型LIRA
LIRA模型:看得懂还能切的准的AI小天才
最近研究者搞出了一个叫LIRA的多模态大模型,不仅能理解人话,还能像米其林大厨切菜一样精准分割图像。来看看这个AI小天才的奇妙表现:
神奇的分割秘诀
“离白色汽车最近的红色巴士”这种火星语也难不倒
LIRA可不是一般的模型,它能:
研究者把这套神操作称为“推理分割”(Inferring Segmentation),跟隔壁LISA家的“常识推理分割”不太一样:
总结
LIRA就像一个眼神超好的AI导购:
看来以后网购再也不怕客服听不懂”我想要左边数第三件但不是最便宜的那件”这种人类迷惑表达了!
科研界的”福尔摩斯与华生”:SEFE和ILVC如何联手破解视觉谜题?
在多模态大模型的奇幻世界里,研究者们就像两名侦探——语义增强特征提取器(SEFE)和交错局部视觉耦合机制(ILVC),携手合作,誓要破解”分割不准”和”理解幻觉”两大悬案。
1. SEFE:让模型从”像素近视眼”升级成”语义狙击手”
2. ILVC:给”幻觉编故事”的模型戴上”紧箍圈”
强强联合的破案记录
这对搭档的战绩包括但不限于:
让分割结果从”土豆汤糊状”变成”高清外科手术级”
把”看图说话”的脑洞从《哈利波特》拉回《国家地理》
成功阻止AI把CEO的秃头识别成”反光乒乓球”
(注:以上幽默案例纯属科研娱乐,真实效果以论文实验数据为准。)
语义增强特征提取器(SEFE)
模块解密:当语义遇上像素的双人舞
这个神奇的模块就像一场精心设计的科技双人秀——
它们共舞的秘诀在于:
这对黄金搭档的组合,就像让毕加索和达芬奇一起画二维码——既有艺术高度,又能精准扫码!
谁说数学不能有趣?揭秘那些”多头怪”的爱恨情仇
今天我们来聊一聊人工智障…咳咳,智能界的”神操作”——多头交叉注意力大杂烩技术!
“多头怪”的晚宴邀请函
想象一下几个长着不同脑袋的怪兽(没错就是多头注意力)围坐在桌前:
史诗级的晚餐派对
它们可不是在简单地吃饭,而是在进行一场跨物种相亲大会!
技术解释(假装严肃版)
其实啊,这就是让模型学会:
专业人士称之为”特征融合”,但我们更喜欢叫它”怪兽们的真心话大冒险”下一次当你看到AI生成的精美图片时,别忘了感谢这些可爱(?)的多头小怪兽们!
就像相亲节目的最后一幕,我们把所有精心挑选的特征手拉手聚在一起——
结果?要么AI醍醐灌顶拍案叫绝,要么死机给你看。(摊手)
交错局部视觉耦合模块(ILVC)
跨越次元的”看图说话”新玩法
在人工智能的世界里,教会机器“边看边说”可比人类婴儿学习要折腾得多。现有的方法就像是一个“近视眼文科生”——光顾着死记硬背单词(token处的embedding),然后在考试时胡乱联想(生成分割掩码)。
现行方案的三大”灵魂缺陷”
人类小朋友学东西可就高明多了——先被闪闪发光的东西吸引,然后指着它咿咿呀呀。我们的新方法就像是给AI装了:
这个创新的”拼图游戏”让AI终于学会了像人类一样:
效果嘛…比起原来那种”闭眼描红”的操作,简直是从盲人摸象升级成了CT扫描!
当AI开始“看图说话”:一场像素与词汇的奇妙约会
想象一下,LIRA(这名字听起来像个意大利咖啡机)突然决定玩拼图游戏:
通过这种“剪贴画→小作文→续写”的魔鬼训练,AI终于学会了一件事——看到狗鼻子就别硬说是香菇。从此,幻觉(Hallucination)从技术问题变成了哲学问题。
实验结果:优于先前最佳方法
LIRA:这位跨界学霸实力有多强?
最新研究发现,AI界的”全能选手”LIRA同学再一次用实际行动证明:谁说学霸不能玩跨界?实验结果新鲜出炉——
跨界成绩单亮点解析
研究人员偷偷透露,LIRA这家伙简直就是学术界的瑞士军刀——要分析文案能掏出阅读理解证书,要处理图片又能变身灵魂画手。更气人的是,它在两个领域的表现都比隔壁那些”专业单科生”来得优秀!
(小声说:建议给LIRA颁发”最会端水AI奖”)
两个AI打架记:大个子和小矮人的性能秘密
实验背景:小哥俩的大比拼
研究人员最近做了件有趣的事:
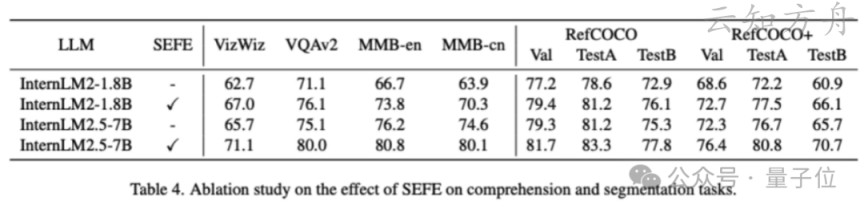
实验结果:意外发现
令人惊讶的是:
有趣的观察
魔幻现实主义版论文精要
研究人员继续在这条神秘的 “AI降幻觉” 奇幻道路上探索。
本次登场的是一位名叫 ILVC 的神奇药剂,它的表现如何呢?
实验结果快报
看来,AI的世界也需要 “醒神丹” 啊!不过下次要不要试试 “咖啡因注入法”?
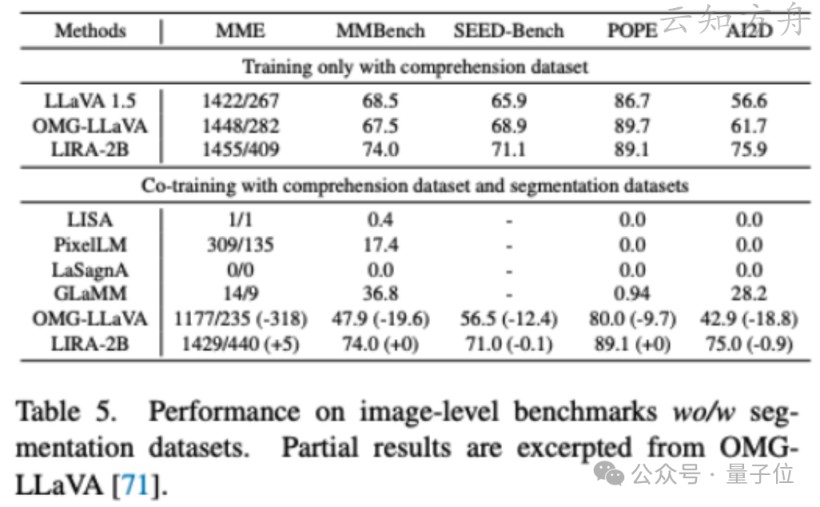
LIRA 大战 OMG:一场数据理解与分割的“内战”
LIRA研究新发现:AI的眼睛里到底藏着什么秘密?
科学研究团队最近推出了一项震撼性的突破——LIRA模型不仅在理解和分割任务上表现优异,甚至还让AI学会了一点神奇的视觉直觉!实验证明,这个小家伙不仅能精准分割物体,连token的logits都开始在悄悄“八卦”物体的属性,仿佛自带一套“灵魂扫描仪”!
主要亮点
研究的终极奥义
LIRA不仅让AI的理解和分割能力原地起飞,还提供了一个全新的视角来减少AI“做梦”(幻觉)的问题!更重要的是,它将token的语义内涵拉进研究范围,犹如打开了AI大脑的“黑盒子”,让未来的研究者们可以直接在里面“挖矿”!
总的来说,这项研究成果让人忍不住大喊:“LIRA,你还有什么惊喜是我们不知道的?”
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章