当AI学会”三省吾身”:字节团队推出”事后诸葛亮”学习法
训练大模型就像教一个固执的天才学生:传统方法是边做题边念叨”这道题应该这么解”,而字节团队的新招数是——先让AI自由发挥,做完题再让它当自己的补习老师。
“做错题本”也能这么高大上?
这套名为”Post-Completion Learning (PCL)”的方法主打一个“先射箭再画靶子”的哲学:
训练阶段:让AI像话唠教授一样,先输出答案,再啰嗦一通自我批评(”我刚才这个回答不够严谨,第三点应该补充…”)推理阶段:AI突然变身酷哥,只吐答案不废话——但此时的它已经偷偷把反思能力腌入味了真实效果:卷王界的”无痛内卷”
测试证明这套方法简直就是“白嫖式进步”:
输出质量:像吃了后悔药一样显著提升推理速度:保持光速不改(毕竟省去了现场自我PUA的环节)额外消耗:零!这大概就是传说中的”台上一分钟,台下十年功”对人类的学习启示
此方法深刻揭示了当代打工人现状:
领导眼中的你:汇报时言简意赅实际上的你:深夜在家对着镜子练习了20遍”刚才我应该这样说…”字节团队这波操作,完美诠释了什么叫“偷偷努力,然后惊艳所有人”。

巧克力引发的财务危机
让我们用小明同学的购物故事来探讨这个充满数学陷阱的日常生活场景:
第一步:巧克力的诱惑*初始资金:50元(好一笔巨款)单价:7元/颗(这巧克力怕是镀金的)购买数量:5颗(小朋友你对甜食的执着让人敬佩)第二步:惨烈的数学运算*首先我们计算小明为这五颗”金”巧克力贡献了多少GDP:5×7=35元*(小明的钱包发出第一声悲鸣)接着计算剩余资金量:50-35=15元*(这时候小明应该能听到钱包的啜泣声)购物后的财务总结*:余额:15元(刚好够买个冰棍缓解被掏空的悲伤)代价:5颗巧克力带来的罪恶感和可能的蛀牙事后反思*:如果你觉得这个过程太过简单,不妨试着把巧克力单价提高到700元一颗…
5×700=3500元 → 50-3500=-3450元*恭喜小明*!他成功在小学阶段就提前体验了信用卡透支的快感!生活小贴士*:下次购买前,建议小朋友先做数学题,再进行消费决策。否则,你可能不是买到巧克力,而是买到一次生动的财务危机教育课程。
方法
大模型也会“偷偷检查作业”?不对称训练让AI学会自我反省!
现有语言模型的“偏科”问题
传统大模型的训练和推理就像一场不允许打草稿的考试——题目问啥就答啥,写完最后一个字就要交卷,连回头检查的机会都没有。比如:
对称训练:模型训练的目标仅仅是“预测到结束符(EOS)”,这意味着它在答题时必须一口气写完整份答案,没有“复查”的余地。推理限制:即使模型在真实应用场景中可能有更好的想法,也只能硬着头皮输出第一个版本的答案,没法自我优化。简而言之,传统AI就像一个从不检查错别字的学生,交卷速度飞快,但答题质量偶尔会“翻车”。
—PCL:让AI学会“悄悄改答案”的黑科技
PCL方法的核心思想非常有趣——训练时让AI假装交卷,但实际上继续偷偷输出改进版,推理时再“装”成什么都没发生!具体来说:
训练阶段:把EOS(传统停止信号)换成“临时结束符”,让AI误以为考试结束了,实际上让它继续输出自我评估(就像学霸写完了标准答案,又偷偷在旁边写了个更优解)。AI因此学会了“内省”:一边答题一边思考“我刚才写的答案靠谱吗?”推理阶段:模型仍然在原先的EOS位置停下,假装自己还是那个只会答题的乖宝宝,但其实心里已经默默完成了答案优化!好处:计算效率不变,但答案质量居然提升了!(就像考试时间不变,但分数提高了)—实验结果:AI学会“作弊”后反而更聪明了?
实验证明,这种“不对称训练”方式不仅能提升模型的自评能力,还能让它回答得更准!比如:
传统模型答题时:“地球是平的。”(糟糕,写错了,但没法改…)PCL训练后的模型:“地球是平的……咦不对,好像是圆的?”(虽然最后只输出“地球是平的”,但其实它默默修正了认知!)这项技术的神奇之处在于——AI在训练时学会了“心里嘀咕”,但实际应用时依然保持高效,简直就是“偷偷用功,明面上不露痕迹”的学霸行为!
下次当你看到某个大模型输出了一条完美的回答,可以合理怀疑——它可能在训练时已经偷偷写过10个版本了!
当AI学霸学会给自己打分:一场机器学习的叛逆青春期
1. PCL方法:从”交卷就跑”到”考后复盘”
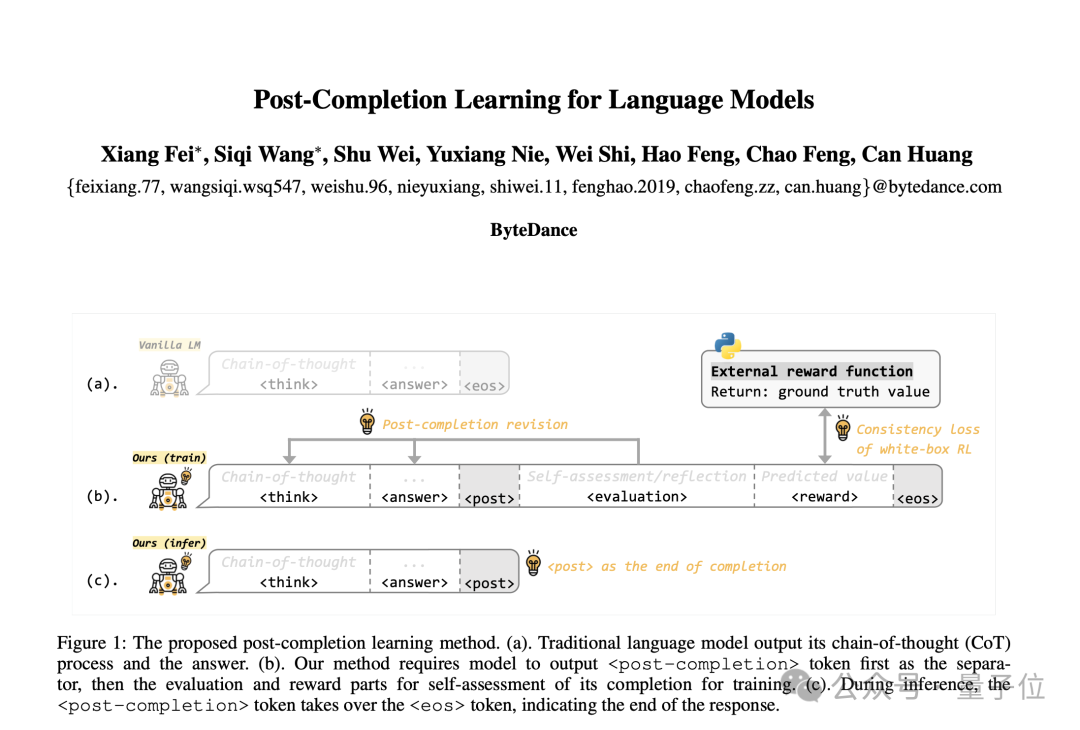
传统AI训练就像考试时 “写完最后一题立刻交卷” 的学生(图a),而PCL方法则是那个 “硬要检查三遍还把草稿纸写满批注” 的学霸:
(b) 训练阶段: 先把”交卷”按钮换成 “临时停笔”,逼AI在后面追加 “本题反思” + “本次模拟考自我评分”。(c) 推理阶段: 当AI看到”临时停笔”标志时,立刻心领神会地 “摔笔起身”——既避免了啰嗦,又保留了批判性思维。2. 白盒化RL:AI的”自学宣言”
现有的强化学习像 “蒙眼走迷宫”:
外部奖励函数如同老师扔小纸条:”第3步+1分!” (但AI根本不知道加分标准) 模型内心OS:”为什么上次撞墙扣分,这次却没事??”PCL的解决方案堪称 “学习方法的革命”:
拆开评分标准:直接把考卷答案发给AI:”注意!这里要写’解’字,步骤分占70%……”
自批自改:AI一边答题一边给自己 “画√/×”,最后和老师的评分比对,逐渐练就 “火眼金睛”。
相当于把学生培养成了 “出题组长”,从此考高分就像呼吸一样自然~
当AI学会给自己发小红花:论白盒化强化学习的一出好戏
1. 传统的奖励设计:AI的黑盒神秘学
“老板,这奖励怎么算的?”——”不关你的事!”传统强化学习像是老板和员工的关系:老板(研究员)定规则,员工(AI)埋头苦干,但奖励机制是个天大的谜团。AI面对结果只会挠头:”我到底是哪一步触发了老板的怒火/微笑?”2. PCL 的白盒化大革命
“罚你 100 块,因为代码里有个分号没对齐!”一致性奖励函数(Consistent Reward Function):让AI终于明白奖励和惩罚的来源,不再是”老板今天心情不好”。透明度++:就像给员工发工资条,AI可以精确知道自己做得好的地方(比如逻辑严谨)和需要改进的点(比如胡说八道)。3. 混合训练框架:让AI接受学霸的调教
“先背课文(SFT),再做应用题(RL),最后期末考(混合训练)”SFT(监督微调):让AI熟读《人工智障免死手册》,打好基础。RL(强化学习):让它实战演练,开始接受社会的毒打。联合优化(PCL式调参):让模型不仅背得熟,还能灵活应用!效果验收
之前的AI:”人类满意度是什么?能吃吗?”现在的AI:”我懂了!我会计算奖励了,我会对齐人类价值观了,我甚至还会发博客解释这一切!”(注:本博客内容纯属娱乐,但不代表PCL不厉害。)
当AI学会了”绕弯子”与”打分数”
各位看官,今天咱们聊聊AI界的”弯弯绕”和”打分狂”是怎么练成的!
一、推理能力训练:让AI学会”绕弯子”
SFT阶段(”手把手教学”):数据集使劲喂,让模型学会Think+Answer两步走。比如问题:”为什么猫会舔毛?”以前的AI:”因为它们爱干净!”(直球)现在的AI:”首先,猫的舌头上有很多倒刺,其次…”(开始绕)GRPO阶段(”考试打分”):答案不仅要对,格式还得骚!写对了给格式分,写错了扣逻辑分。目标:让AI的回答既像学霸又像编辑强迫症。二、评估能力训练:当AI成了”打分狂”
SFT阶段(”模仿老师改卷”):先让AI看标准答案和高分示例,学会如何给推理过程打分。现在的AI不仅能答”42是宇宙的终极答案”,还能评”你这个论证少了7分哲理味儿”!GRPO阶段(”评分一致性挑战”):设计了一致性奖励——不能乱打分,分数要稳定!假如AI给同一份答案昨天90今天59,那就得被罚写代码100遍。三、终极混合训练:左手推理,右手打分!
统一框架下,SFT+GRPO 双模式混合训练。像调鸡尾酒:推理能力 + 评估能力 + 奖励优化,一起摇匀。目标是让AI不仅会做题,还要会批改作业!如此一来,未来的AI不仅能好好答题,还能精准评判你的答案——你想忽悠它?它可能比你的教授更严格!
实验结果
PCL实验大揭秘:当AI训练方法开起了”武林大会”
实验一:武林门派大比拼
作者就像个武术比赛裁判,让各路训练方法上场比试:
SFT派:像个老实学生,只知道模仿老师笔记RL派:活像赌场里的赌徒,全靠运气摸索PCL派:像开了外挂的学霸,既会模仿又有主见结果证明PCL简直是”武学奇才”,轻松KO其他门派!
实验二:拼装模型积木大赛
作者玩起了”乐高式研究法”,看看PCL究竟哪块积木最重要:
移除评估SFT → 模型秒变”失忆老人”去掉一致性奖励 → AI开始”精神分裂”完整PCL → 像个戴着智能眼镜的福尔摩斯事实证明每块积木都不可或缺,拆掉任何一块都会让AI智商掉线!
隐藏彩蛋
这场”武林大会”最精彩的发现:
PCL不只是简单的”1+1=2″,更像是魔法配方评估SFT和一致性奖励就像自动驾驶的”双保险”混合策略让AI既有学霸的严谨,又有艺术家的创意最后实验证明,想调教出聪明的AI,就得像个米其林大厨——各种调料缺一不可!
论文实验结果:当AI模型开始”自我反思”
1. 数学推理:不再是”9×9=81,其他随缘”
Qwen-2.5:提升显著,不再把”微积分题”误当成”买菜计算”。Llama-3.2:甚至能在证明”1+1=2″时不偷偷求助搜索引擎了。2. 逻辑推理:终于学会”因为所以”而不是”可能大概”
以往:”如果大前提是错的,那结论该怎么编?”现在:”前提错了?那就干脆别推了!”(逻辑洁癖初显)3. 消融实验验证:不是瞎蒙的!
蒸馏/强化学习?效果一般(AI:”别老让我学别人!”)
自我评估才是关键(AI:”原来我可以自己检查答案???”)
结论
模型终于学会“先思考,再说话”,不再是一台只会瞎猜的”概率计算器”。这一改进使得AI的逻辑能力直逼“数学课代表”水平,可喜可贺!
结论
PCL方法:你以为AI在训练,其实它在玩”不对称美学”
EOS后的神秘空间:AI的”垃圾堆”里挖出宝藏
传统AI训练:”打完EOS标记就收工,后面的东西都是废纸!”PCL方法:”等一下!这片’废弃训练场’里可能有恐龙化石!”结果:愣是在大家习惯性忽略的地方,发现了自我评估能力的金矿原来AI的”草稿纸”比正式答卷更有看头“垃圾桶考古学”成为AI训练新时尚强化学习”开盒”行动:黑箱表演变透明橱窗
传统RL:”我在黑箱里扭来扭去,你们猜我在学啥?”PCL方法:”都让让,我要把魔术师的帽子捅个洞!”观众:”原来你刚才是在练习后空翻,不是中风啊!”系统:”既然你们都看见了,那我就…翻得更标准一点?”效果:AI从”谜语人”进化成”解说员”,成绩反而上了光荣榜训练界的”非对称时尚”:冬练三九,夏练三伏
传统方法:”训练穿羽绒服,推理也得裹同款”PCL的时尚哲学:训练时:身穿15公斤重的训练服,头戴VR设备,边深蹲边背圆周率推理时:换上休闲T恤,云淡风轻地说出”答案是3.1415926…”业内惊呼:”这不就是学术界苦苦寻找的’学霸型节能模式’吗?”未来展望:这可能不是妙招,是”作弊器”
训练效果↑↑↑,推理成本零零零其他实验室:”我们现在退货原来的方法论还来得及吗?”预测:很快会有论文标题出现《论PCL为什么还没成为行业标准》—本文研究就像给AI喂”智慧复合维生素”——训练时大把吃,推理时自动吸收,还不会便秘(指计算卡顿)。科技圈的”减肥达人”们又要开始新一轮方法论瘦身运动了!*© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。