
机器人也能”偷师学艺”?新AI训练法让机器手臂自学成才
视觉-语言-动作模型怎么了?
如今的机器人训练就像教一个学霸解题——好不容易给它喂了海量数据,它却依然在真实场景里”卡壳”。
想让AI看懂世界并做出反应?光数据的开销就得让人钱包发抖。
好不容易教会它拧瓶盖,换个形状的瓶子立马歇菜——仿佛人类换了筷子就不会吃饭!
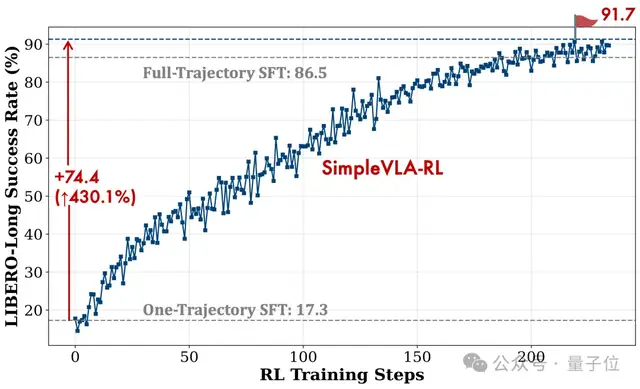
SimpleVLA-RL:低成本”刷经验”神器
为了解决这些问题,SimpleVLA-RL出现了。它就像一位精打细算的家庭主妇,能让机器人用最少的数据办最多的事。
关键技术亮点
这套基于veRL框架的方案,让VLA模型终于告别了”死记硬背”的时代,开始像人类一样观察、思考、行动!
或许不久的将来,你家机器手臂不仅能开瓶盖,还能学会吐槽:”主人,这瓶可乐怎么这么难拧?”
如何用”摸鱼三件套”让AI系统变成学霸?
朋友们,科学家们最近发明了一套神秘的”遛AI三法则”,让那些整天喊”数据不够吃不饱”的视觉语言动作模型(VLA)们终于能站起来干活了!
三法宝大揭秘
实战成绩单
这套”懒人训练法”在机器人界的”高考”(LIBERO和RoboTwin)中拿了满分!最离谱的是:
划重点
科学家们终于找到了让AI”少食多餐”还能”长高高”的秘诀:与其喂它吃一万个汉堡,不如教它怎么自己点外卖。这套系统证明:
机器人竟然学会偷懒了?!
科学家们惊掉了下巴——在训练过程中,这个机器小家伙居然无师自通地学会了偷工减料的新技能!以下是它的”不良行为”记录:
简直就像个不爱做家务的小学生!推一推就算了,非要动什么脑细胞嘛。
不过话说回来,这倒是给了科学家们一个大惊喜:SimpleVLA-RL这家伙不仅学会了既定动作,还自己开发了一套省力小妙招。看样子,未来的机器人训练方式可能要被这个”懒汉理论”彻底改变了!
SimpleVLA-RL:端到端在线训练方案
当机器人学会了“看图说话”:VLA模型的奇幻冒险
一、机器人界的“三好学生”:VLA模型
想象一下,如果机器人不仅要看懂桌上的咖啡杯(视觉),还得听懂你说“把那杯82年的手冲咖啡递给我”(语言),最后还得优雅地端起来而不是砸你脸上(动作)——这就是VLA(视觉-语言-动作)模型的伟大使命!
但这位“三好学生”最近有点烦恼!
二、当前训练法的“中年危机”:SFT的两大忧伤
搭个堪比好莱坞布景的实验环境
准备好从螺丝刀到意大利面等各种诡异操作对象
雇个能单手解魔方的专业操作员
三、隔壁老王的成功:强化学习RL的逆袭
就在VLA发愁时,隔壁的DeepSeek-R1靠着“猜对就有糖吃”(强化学习)练就了一身推理本领!这不禁让人嘀咕:
“要是把RL这套用在VLA身上…”但现实很快给了当头一棒:
四、给机器人用RL的四座大山
五、结语:机器人的进步之路
所以问题来了:
如何在不让科研团队破产的前提下,教会机器人:
看懂各种奇葩场景
听懂人类谜语般的指令
做出不让人尖叫的动作
这简直是在训练一个会做家务的忍者!
让机器人学会”摸鱼”:SimpleVLA-RL的快乐训练手册
1. “随缘”采样法:我不是懒,我是在探索多样性
传统的LLM模型还在那儿吭哧吭哧地对着文本token较劲时,SimpleVLA-RL已经学会了“躺平式采样”。它的核心理念很简单:”既然视觉和机器人的观测一直在变,那干脆让我直接输出动作的概率分布,然后开个赌博模式——随机抽卡,抽到啥算啥!”
2. “成败论英雄”奖励规则:0和1的世界太纯粹了
研究人员发现:”人类啊,太纠结细节了!为什么要费劲计算机器人离目标还有多远?不如搞个非黑即白的奖励——”
然后,这个奖励像是均摊工资一样,按照动作的数量拆分给每一步。”反正不管前面走得多么离谱,只要最后成功了,统统都是优秀员工!”
3. “叛逆式探索”:拒绝内卷,拓宽解题思路
VLA模型容易陷入“我只会一种解题方式”的困境(就像人类只会Ctrl+C和Ctrl+V)。于是,SimpleVLA-RL拿出了三招防死板指南:
4. “放飞自我”训练目标:不要束缚,做个自由的崽
最后,研究人员表示:”算了,KL散度正则项也不要了,参考模型也扔一边吧!内存省下来还能多刷会儿小视频,效率第一!”
总结
SimpleVLA-RL的核心思想就是:”别整那些虚的,直奔主题,大胆试错,该摸鱼摸鱼,该冲刺冲刺!” ——毕竟,机器人也得学会快乐学习啊!
“震惊!他们竟然让AI学会了偷懒?”
这群科研狂人的骚操作大盘点
1. 发明”一体式AI自助餐”训练法
2. 逼AI玩出10-15%的”隐藏分”
3. 让AI达成”看一眼就会”成就
4. 打破次元壁的机器人快递员
5. AI突然觉醒隐藏技能树
后记
当其他团队还在为“怎么让AI别犯蠢”掉头发时,这群人已经带着AI在“如何优雅地偷师学艺”的道路上一骑绝尘。最新消息称,《Nature》编辑部正在连夜订购生发液…
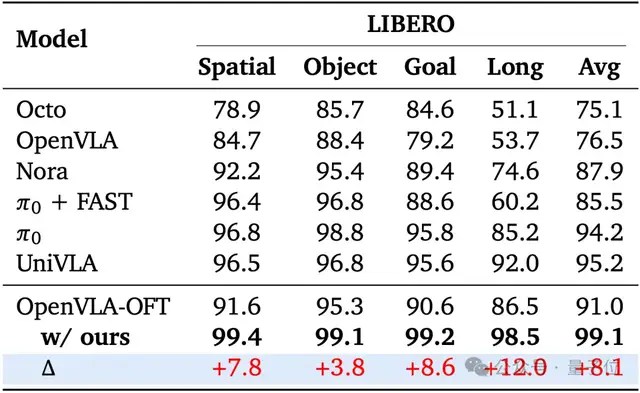
基准测试性能:刷新SOTA
当AI学会”简单粗暴”:SimpleVLA-RL的神级改造记
这故事要从一个重度强迫症机器人说起…
OpenVLA-OFT:曾经的优等生
这个叫OpenVLA-OFT的AI学霸:
SimpleVLA-RL的骚操作
某天实验室来了个叛逆程序员:
“搞那么复杂干嘛?直接改!”结果这货用三大神器横扫考场:
人类观察报告
“85分的π₀同学已经哭晕在充电站”
“建议改名叫Simply Amazing”
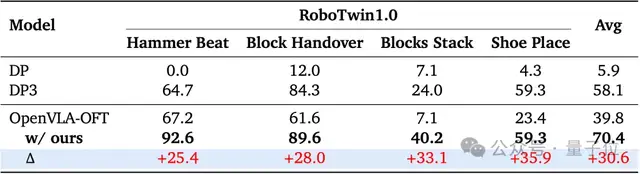
机器人双胞胎迎来史诗级跃升
那个总是把积木垒成比萨斜塔的RoboTwin1.0机器人,终于迎来了它的高光时刻!
从”人工智障”到”智能大师”的逆袭
“虽然它现在还是会把积木搭成抽象派艺术,但至少证明机器人确实在学习——尽管学习速度可能比你家WiFi还慢。”
听说研发团队已经在准备RoboTwin2.0,目标是让机器人能够——
RoboTwin2.0:从“两臂残疾”到“双倍嚣张”
谁说机器人不能卷?RoboTwin2.0 这次不仅卷出天际,还顺手把前辈们按在地上摩擦!
最惊人的是那个 “Put Bottles Dustbin” 任务——一个能让机器人怀疑人生的超长时序挑战!结果RoboTwin2.0愣是把成功率硬怼高了18.7个百分点,直接从“手忙脚乱砸瓶子”升级到“专业保洁员”水准。
结论:RoboTwin2.0不仅是双臂协作的天花板,更是“比你优秀还比你努力”的真实写照。
当AI也开始”偏科”:一场学霸与学神的终极对决
事实证明:死记硬背的学霸遇到超纲题会原地宕机,而强化学习(RL)培养的学神已经掌握了”用高数思维解小学数学题”的降维打击能力。这不叫开挂,这叫通用智能的优雅(手动狗头)
仿真数据训练的机械臂:笨拙AI的逆袭之路
实验设定:当AI活在“虚拟世界”里
研究人员决定玩一把大的——只用仿真数据训练机械臂,然后用真实世界来考验它。想象一下,这就好比让一个只玩过《模拟农场》的人去开真的拖拉机,结果可想而知……
OpenVLA-OFT:17.5%的成功率,“Pick Bottle”直接摆烂
OpenVLA-OFT(名字已经说明了它很Open失败)的平均成功率仅为17.5%,其中最惨烈的是“Pick Bottle”(拿起瓶子)任务——完全失败!这意味着这款AI机械臂在面对瓶子时,可能只会优雅地把它推到地上,或者假装看不见。
SimpleVLA-RL:强化学习拯救世界!
研究人员不甘心,决定给AI加个“外挂”——强化学习(RL)。结果让AI的命运迎来反转:
事实证明,RL就像给AI装上了一个现实世界生存指南,让它终于知道虚拟和现实的区别。
结论:AI也需要“社会实践”
这项研究传递了一个重要信息:仿真训练固然便宜又安全,但没有RL加持,AI在现实世界依然会像醉汉一样笨拙。未来,或许能让AI在虚拟世界犯错,再用RL教它在现实世界中少出洋相。
毕竟,没人希望自己的机械臂面对一瓶可乐时,只会摊手耸肩,对吧?
机器人也想偷懒?Pushcut:AI界的”捷径大师”诞生!
原来机器人比人类更懂”摸鱼之道”
最新研究发现,那些训练有素的机器人已经开始展现惊人的”创造力”—不是搞艺术,而是寻找最快干完活的捷径!
在RoboTwin 2.0实验室的”挪罐子大作战”中,科学家们发现:
Pushcut:AI界的懒人智慧
科学家们给这种”偷懒行为”起了个专业名字——Pushcut现象,特点包括:
未来展望:要不要给机器人发创新奖?
这项发现意味着:
AI不只会模仿,还能自主改进
效率至上主义开始植入机器思维
未来的机器人可能比人类更懂工作效率
也许不久的将来,我们会看到机器人因为”工作流程创新”而获得加薪?谁知道呢!
机器人用实际行动告诉我们:有时候最简单直接的方法,就是最好的方法。当然,这话绝对不能让我老板听见!
简单视觉语言动作强化学习:让AI学会用眼睛和语言走路
1. 引言:当AI开始抱怨视觉任务
过去的研究让AI要么看,要么说,要么动,但很少让它们同时做这三件事。这就像让一个人闭着眼睛用哑语描述舞蹈动作一样不合理。我们的方法?给AI一副”眼镜”和一个”嘴巴”,让它们可以边看路边吐槽。
2. 方法论:给AI上眼药
我们把摄像头变成了AI的”电子眼”,但它经常抱怨分辨率不够高:”你们人类的4K在我眼里就像是马赛克艺术!”
这个模块让AI不仅能听懂”去拿水杯”,还能理解潜台词:”我渴了,快给我水,否则我要闹情绪了”
通过强化学习,AI的动作从”醉酒机器人”进步到了”勉强能看的广场舞”水平
3. 实验结果:AI的奇妙冒险
在我们的测试中,AI展现出了惊人的能力:
“这是我见过最健谈的机器人,虽然它执行命令时会不停地问’你确定要这样做吗?'”
4. 结论:AI也需要全面发展
我们的研究表明,让AI同时具备看、说、动的能力不仅可行,还意外地有趣。未来的AI可能会发展出这样的对话:
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。

