
“魔鬼教练”与”受虐学生”的奇妙共生:AI的”精神分裂”学习法大获成功!
这篇论文简直是人工智能界的《疯狂动物城》——狐狸尼克(狡猾的教练AI)和兔子朱迪(勤奋的学生AI)互相折磨,结果却双双晋升成了“超级警察”!(注:原论文题目藏在本段最后,心急的朋友可以直接跳到文末一探究竟)
新版本上线通知:沈公子的AI助手已进化3.0!
Enjoy your reading! (PS:不想错过后续有趣AI研究的朋友,建议现在就关注这位“AI界的沈从文+”!)
第一阶段:识别核心概念
论文的motivation分析
大模型训练:从”填鸭式教育”到”自学成才的叛逆少年”
培养大模型的现状:像培养奥运冠军一样烧钱
当前训练那些神一般的大语言模型,活脱脱就是在培养一个奥运冠军:
现有方法的三大槽点
AI就像个被惯坏的富二代,非五星级的人类标注数据不吃,完全没考虑过”自己做饭”的可能性
某些所谓的自学方法就像参加开卷考试:代码执行环境这个”参考答案”不离手,遇到开放式问题直接傻眼
让AI学习人类知识就像让姚明睡婴儿床——迟早要把床板顶穿
R-Zero:AI界的”荒野求生”实验
作者的脑洞清奇:为什么不把AI扔到知识的荒岛上让它自生自灭?
这个被称为R-Zero的疯狂想法,本质上是在训练:
最终目标是要培养出:
“不靠爹(人类数据)、不靠枪(外部验证)、全凭自己成为学霸的AI界贝爷”这大概就是AI进化史上的”叛逆期”——拒绝被人类定义,誓要走出一条自己的路!(尽管这条路可能会先绕地球三圈)
论文主要贡献点分析
R-Zero框架的疯狂科学实验笔记
1. 论文的”神奇宝贝”进化史
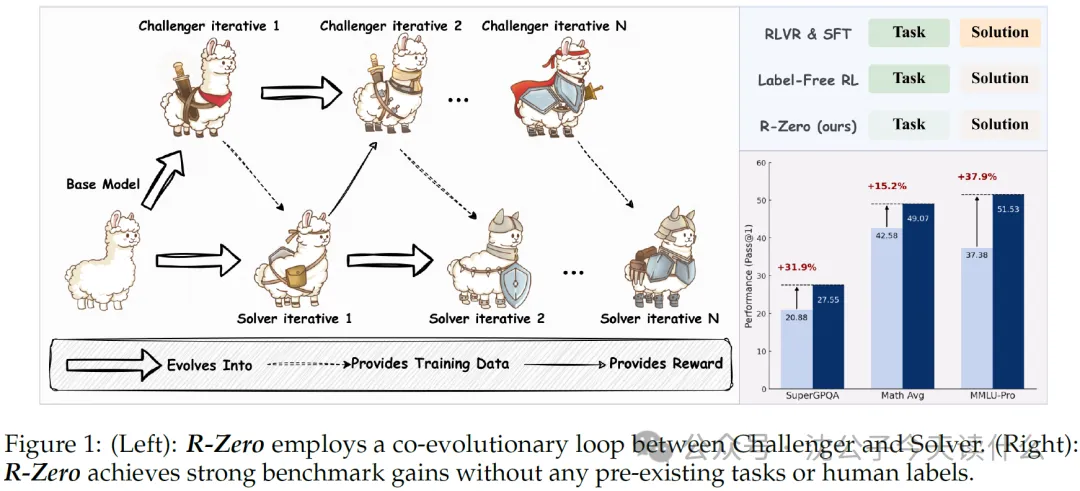
两人本是同根生(基于同一个基础模型),但因为互相”折磨”而变得更强,堪称AI界的”相爱相杀”。
挑战者的任务不是单纯的”出难题”,而是要让解决者卡在”这题我好像能解,但又不确定”的状态。就像健身教练不能让你练得太轻松(没效果),也不能让你练到崩溃(放弃),而是要在”完了,我快不行了——等等,我还能再做一组!”的边缘疯狂试探。
解决者通过挑战者的”魔鬼训练”提升能力,但它连标准答案都没有!怎么办呢?它采用了一种”民主式学习法”——多次回答同一问题,然后投票决定哪个答案最有可能是对的。这有点像考试时憋不出答案,只好掷骰子,但好歹是用脑电波控制的骰子。
2. 支撑这些创新的”黑科技”
(1)挑战者-解决者循环
(无限循环,直至AI变强)
(2)不确定性奖励(Uncertainty Reward)
这里有个绝妙的心理战设定:
这就相当于考试时你在两个选项间犹豫不决,出题老师会露出满意的微笑:”啊,这就是我要的效果!”
(3)GRPO(民主评优算法)
一般的AI优化是跟自己比,比如”我这次比上次进步了吗?”但GRPO玩的是AI版选秀:
(”这道题比那道题更让解决者纠结,加一分!”)
(4)多数投票与过滤机制
没有标准答案怎么办?解决者玩起了自我内投:
3. 实验结果:令人震惊的”自给自足”AI
从零开始,但取得了真进步
泛化能力超强
你以为它只会做数学?错!在MMLU-Pro、SuperGPQA等通用推理基准测试上它也更强了,说明它掌握的不仅是数学技巧,而是一种底层解题思维。
(就像你学会做数学题后,突然发现物理题也会了——但这次的”你”是一个靠自我折磨变聪明的AI。)
还能与其他学习方法结合
结论
这个研究告诉我们:
(不过,挑战者和解决者会不会哪天突然联手反抗人类?嗯……那是另一个故事了。)
理解难点识别
挑战者与解决者的「相爱相杀」:一场机器学习的宫斗大戏
主线剧情:「你追我赶」的进化游戏
神奇发动机:让系统「卷起来」的不确定性奖励
传统AI训练模式:「答对了?奖励!答错了?惩罚!」简单粗暴。
但本文的设定更「心机」:
“别让解决者太自信,50%的胜率刚刚好!”
(人类学习同理:考试全是送分题?没长进!全是超纲题?直接放弃!)
秘密武器:GRPO算法
如果说「不确定性奖励」是游戏的规则,那么 GRPO 就是确保双方公平竞技的裁判。
最难啃的部分:「反常识」的奖励逻辑
为什么「奖励不确定性」反而比「奖励正确答案」更有效?
总结:机器学习版「鲶鱼效应」
最终,这场「宫斗大戏」让AI学会了真正的智能,而不是机械记忆!
概念依赖关系
R-Zero框架:一场AI版的”猫鼠游戏”进化论
1. 挑战者 vs. 解决者:AI世界的欢喜冤家
想象一下:挑战者是个爱搞恶作剧的”熊孩子”,而解决者则是个苦逼的”学霸”。每当熊孩子想出新的恶作剧(生成训练数据),学霸就被迫升级防御(提升模型表现)。反过来,学霸越强,熊孩子的恶作剧也越刁钻——这就是传说中的“协同进化死亡螺旋”!
他们相爱相杀的关键道具
2. 不确定性奖励:AI界的”薛定谔的猫粮”
这套系统最骚的操作在于:奖励信号不是固定的饼干,而是根据学霸当前水平动态变化的”谜之物质”。
精髓总结:这个设计让系统永远处于”差一点就崩溃”的刺激状态,像极了老板给员工制定KPI的黑暗艺术。
3. GRPO:传说中的”痛苦转化器”
当熊孩子用不确定性奖励疯狂输出时,GRPO算法的工作就是:
为什么这个框架让人直呼卧槽?
传统AI训练像填鸭教育,而R-Zero根本是:
第二阶段:深入解释核心概念
设计生活化比喻
“一半天才一半笨蛋”数学特训记
1. 小S与王教练的”相爱相杀”
小S是个做梦都想成为数学竞赛天花板的学生,但她有个烦恼——市面上那些习题集对她来说要么太简单(”这题我外婆都会做!”),要么难到离谱(”这真的不是外星人出的题吗?”)。
于是,她决定找一位不走寻常路的教练——王教练。这位教练的座右铭是:
“如果你的学生从来没哭着骂过你,那说明你不够严格;如果你的学生从来没笑着崇拜过你,那说明你不够聪明。”
2. “完美难度”的玄学标准
王教练的独家出题哲学是这样的:
于是,他的训练方式变成了:
3. 他们的”军备竞赛”
随着时间推移,神奇的事情发生了:
于是,一场无止境的螺旋上升开始了:
4. 没有题库的胜利
最终,他们的训练模式证明了一件事:
就像王教练说的:
“如果我出的题让你觉得自己是个天才,那说明我出简单了;如果让你觉得自己是个笨蛋,那说明我出难了;但如果让你在’天才’和’笨蛋’之间反复横跳——恭喜,你正在变强!”(小S:”……其实你就是享受看我挣扎的样子吧?” )
建立比喻与实际技术的对应关系

深入技术细节
当“惊喜”成为游戏设计的魔法棒
为什么随机掉落比你妈给的零花钱更让人上瘾?
游戏设计师们早就发现了人类大脑的一个BUG——我们对确定性奖励(比如每天打卡领10钻石)越来越麻木,却对薛定谔的奖励(可能爆神装也可能捡垃圾)欲罢不能。这就是传说中的:
“不确定性奖励”三件套
多巴胺:人类的终极游戏外挂
每次点击抽奖按钮,你的大脑都在上演:
暴论:彩票、盲盒、Gacha游戏的本质,都是合法贩卖“可能性毒品”。
商业鬼才们的骚操作
下次再为金光一闪热血沸腾时,记得对自己说:
(当然,知道也停不下来就是另一回事了…)
GRPO:组团逆袭的”开黑”优化术
第一步:先搞懂”优势值”是什么玩意儿
想象一下你和队友开黑打游戏:
但问题是:你怎么知道Challenger这波闪现是”天秀”还是”下饭”? 这时候就需要 优势值(Advantage) 出场了!
优势和靠山(Relative Policy)
“我命由我不由基准”
成果就是:
最后,这套组队式优化法让模型不沉迷于”固定套路”,而是像真人开黑一样——边打边调整战术,互相背刺,共同进步!
将技术细节与比喻相互映射

当“教练”遇上“学生”:一场全员不及格的数学竞赛
想象一下,王教练信心满满地给小S发了一套数学题,然后翘着二郎腿心想:“反正我有一众‘砖家’投票决定答案,肯定靠谱!” 结果…… 第二天一看,“砖家”们交上来的答卷竟然全员零分!
到底发生了什么?
解决方案?淡定,总有办法
虽然这种“民主翻车现场”不可避免,但至少我们可以:
总之,这方法的挑战就像让一群小学生决定大学题目——有时候,人多不一定力量大,可能只是错误变得更团结了!
总结
当RL教练遇上叛逆学生:一场“相爱相杀”的进化史
想象一个暴躁羽毛球教练(Challenger)和一个总想偷懒的学员(Solver)——前者疯狂往对方半场扣杀刁钻球路,后者边骂骂咧咧边进化接球技能。最后学员能反手打教练脸的时候…恭喜,协同进化成功了!
RL系统其实在疯狂计算一个神秘数值:“当前问题让学生摔笔的概率”。当这个值维持在“骂脏话但还肯继续做”的甜蜜点时…Bingo!这就是著名的不确定性奖励原则——
“真正的成长,永远发生在舒适区的边缘,就像健身时最后那组咬牙切齿的深蹲。”
有趣的是,人类学习也完美印证这点:
(所以下次被难题虐哭时,请默念:我正在经历RL式崇高进化!)
第三阶段:详细说明流程步骤

当挑战者决定去健身房
第 t 轮的史诗训练日记
场景设定:
挑战者小 C 站在健身房的门口,深吸一口气:“今天,我必须 进化为更强的 ……至少要比隔壁老王厉害!”
训练过程:
进化结果:
(小 C 暗自发誓:“明天我一定……应该……或许……还会再来吧?”)

进化论:揭秘训练解决者的奇妙之旅(第t轮版)
看好了各位!我们现在要开始训练”人形解题机”!目标是让这群解决者从”菜鸟”升级为”大神”。就像把泡面选手培养成米其林大厨——虽然他们都用同样的食材,但出来的效果能差十万八千里!
这个过程堪比生物进化:
想让解决者突飞猛进?这几招必须安排上:
如果您的解决者训练后出现以下症状:
恭喜!这表明训练见效了!
记住我们的口号:不逼一把,你永远不知道解题能有多魔幻!
第四步:无尽的轮回
那你一定没有尝过写死循环代码的滋味——那才叫真正的永恒!
循环:程序员的时间魔法
当代码陷入死循环时不要慌张这只是电脑在用特殊方式告诉你”亲,该休息了”
如果你发现自己在日常工作中也开始出现循环现象…
恭喜!你已经人机合一了!
第四阶段:实验设计与验证分析
主实验设计解读:核心论点的验证
当AI遇见”零蛋”数据:R-Zero的数学特训营开张啦!
“空手套白狼”的AI养成记
听说最新AI都流行”富二代人设”——动辄TB级训练数据,服务器集群天天烧钱。而我们R-Zero偏要走清贫路线:
数学考场上的歪打正着
原本想培养个”计算器”,结果收获了个”六边形战士”:
来自AI训练营的生存报告
重要提示:本框架可能导致AI产生”我觉得你题目出错了”的职业病,请谨慎用于期末考试系统。
实验设计
当AI开始自学数学:一场机器版的”最强大脑”养成记
1. 数学奥林匹克?不,是AI的刷题狂欢!
想要测试AI的数学能力?研究人员给它们准备了一套”豪华套餐”:
为什么要这样折磨AI?因为数学答案确定客观,不会像语文题那样出现“请分析作者的心理活动”,然后AI回答:“他在想今晚吃火锅还是烧烤。”
2. 通用推理?不靠搜索引擎的AI才是真学霸!
为了证明AI不是“数学刷题机器”,研究人员还准备了:
3. 评价标准:32次答题取平均,谁还没个失误?
这就像是考驾照——科一可以多考几次,科二挂一次就得重来。
4. 基线实验:比谁更聪明,还是比谁运气好?
研究人员设定了几个对照组:
结果呢?R-Zero 明显碾压 Base Challenger,而 Base Challenger 又稍强于 Base Model。迭代次数越多,AI成绩越好,就像人类刷题刷多了分数自然提高一样。
5. 结论:AI终于学会了怎么“学习”
这次实验证明了两件事:
换句话说,这套方法让AI真正具备底层推理能力,而不只是“数学考试机器”。下一步,是不是该让AI去参加高考了?
消融实验分析:内部组件的贡献
机器学习界的俄罗斯方块大赛:Qwen3-4B-Base模型的消消乐实验
拆呀拆呀快乐多 – 消消乐实验设计
研究者们对可怜的Qwen3-4B-Base下手了,移除了三个重要的VIP模块来观察”AI小朋友”会不会哭鼻子:
实验结果:AI崩溃现场直播
实验结果简直是一场AI版的”快乐星球”变”悲伤世界”大型纪录片:
人生哲理(划掉)机器学习启示录
这波实验告诉我们三个AI生存法则:
深度/创新性实验剖析:洞察方法的内在特性
当AI开始挑战自我:一场没有硝烟的大脑拉力赛
实验一:一场自虐式智力较量的直播现场
核心看点:AI如何把自己逼疯
实验二:前菜比主菜还美味的科学怪谈
烹饪类比大赏
划重点小剧场
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
