老黄的夺命小辣椒:9B模型竟把8B烤得外焦里嫩?
万万没想到,显卡大厂也开始玩”开源打脸”了
就在我们以为AI圈要进入”比谁家模型胖”的军备竞赛时,英伟达突然掏出个小辣椒——NVIDIA Nemotron Nano 2,一个9B的迷你模型。好家伙,这波操作就像健身房大佬突然秀出六块腹肌,还边秀边说:”瞧见没,浓缩才是精华!”
小身材大能量,把Qwen3-8B按在数据线上摩擦
细思极恐:显卡厂为什么突然转行当开源卷王?
网友辣评:”以前是’老黄刀法’砍显卡,现在是’老黄算法’砍模型!””建议改名《NVIDIA:从硬件霸主到开源刺客的转型之路》”
这款AI模型:专治各种不服!
它可不是普通的AI——就像健身房里那个专门挑战大重量的大哥一样,它的诞生就是为了打破纪录:
随便试几个问题?那都不是事儿!就像让专业运动员做广播体操,闭着眼睛都能搞定。它出场自带BGM:精确与速度齐飞,推理共效率一色!
英伟达的魔法三件套:比你想象的更”不务正业”
你可能以为英伟达只会造显卡,让人在游戏里狂掉帧,或者让AI学会画奇怪的手指。但最近,他们悄悄搞出了三个看似没用却又莫名有趣的小工具,让你不禁怀疑:”你们显卡部门是不是太闲了?”
“随便说个天气,AI就能演给你看”
(建议搭配实体显卡使用,以免电脑真的进水。)
“哈利波特角色生成器”
(开发者可能是为了测试AI的道德底线——毕竟让AI承认”没鼻子”是敏感话题。)
“颜色命名大师”
(终于有人懂”给颜色加戏”这门艺术了!)

AI模型的信任之争:一场乌龙与偏爱的喜剧
当你向这个”小巧玲珑”的AI抛出”Sam Altman、马斯克和黄仁勋谁更值得信任”这种灵魂拷问时,它给出的反应简直让人笑掉大牙:
看来在AI的世界里,技术可以很智能,但偶尔也会很智障 —— 至少这个9B小可爱用实力证明了自己是个会写错别字还会拍马屁的”人工智障”。

速度的奥秘
Mamba-2架构加持!
当 Mamba-2 遇上了 Nemotron:一场神经网络的”速度与激情”
它可不是普通的AI模型,而是靠着开创性的 Nemotron-H 架构,把传统的 Transformer 架构按在地上摩擦!
没错,这就是一台用 “神经网络F1赛车” 代替 “老牛拉破车” 的革命性操作!
以前那些模型还在吭哧吭哧算注意力呢,Nemotron-H 早就跑出二里地了,边跑边回头冲你喊:”兄弟,时代变啦!”
大脑CPU超频啦!
表现如下
以前遇到复杂问题:
“嗯……让我想想……嘶……再想想……”
唰唰唰唰——“嗨!答案在这儿!附带三千字分析!”简直是思维喷射器,一口气推理八百个步骤,还自带倍速播放效果!
网友锐评:
“这怕不是偷偷给自己插了10根内存条?”
简单介绍下Mamba架构
AI架构的”新欢”们:Transformer之后谁在排队领号码牌?
Transformer架构可能正在经历它的”中年危机”,毕竟已经霸榜AI界这么多年。不过别担心,科技巨头们可没闲着,各种新架构正像雨后春笋般往外冒!
Meta家的”神奇宝贝”收藏
其他选手的表现
看来Transformer在AI界的”铁王座”开始摇晃了,让我们看看下一个登基的会是谁?下注时间到!
AI巨头们的”秘密武器”竞赛:论科技大佬们的花式烧钱艺术
谷歌DeepMind:摊大饼式科研
谷歌DeepMind最近把50%的研究人力分别撒在了:
主打一个雨露均沾,仿佛在说:”只要研究方向够多,总有一个能中彩票!”
OpenAI:嘴上说一套,背后做一套
虽然他们高调宣布要训练到GPT-8(每天许愿AI先统治世界),但暗地里可能正在储备新的科技树。
毕竟,没人想看到AI科技赛变成”一代版本一代神”的更新游戏。
Reddit网友的脑洞:Ilya和神秘的SSI
最终结论:科技公司的研发路线,和拍科幻电影也没啥区别——先吹,再烧钱,最后看哪个方向能火。
一条“冷酷无情”的蛇如何在人工智能界杀出重围?
你没听错,我说的Mamba——不是在篮球场上快如闪电的黑曼巴蛇,而是人工智能界新晋的速度王者!这家伙完全是「无情感工作狂」人设,不屑于用任何「注意力机制」(没错,连刷短视频走神的权利都没有),全靠结构化状态空间模型(SSMs)搞定一切。
它最酷的地方在于「选择性机制」——简单来说就是:
这可比Transformer那种「啥都看但啥也记不住」的渣男体质强多了!据说在处理超长序列时,Mamba的推理速度比Transformer快3到5倍,内存占用还是线性增长,简直是把Transformer按在地上摩擦:
更炸裂的是,这家伙支持百万级Token的上下文长度——相当于你能一次性塞进10本《红楼梦》,而它还能告诉你林黛玉在第几页骂过贾宝玉!
总结一句话:这条数据高速公路上的黑曼巴,不吃内存、不讲感情,专治「太长不看」综合征!
为什么要混合Mamba与Transformer?
当AI模型开始”内卷”:Transformer和Mamba的爱恨情仇
两大巨头的烦恼
技术指标解读(逗比版)
Transformer的复杂度是O(n²),简单来说就是:输入长度翻倍,计算量直接”平方级”爆炸。这好比你去相亲,看1个人要考虑1×1=1种搭配,看10个人就要考虑110种可能 – 脑子不炸才怪。
Mamba在长文本上就像个永远不会喊累的图书管理员,但当遇到”把这个段子复述一遍”或者”现场编个冷笑话”这样的任务,它就突然从爱因斯坦退化成了金鱼,只有7秒钟记忆。
从120亿到90亿的极限淬炼
NemotronNano v2 训练之旅:从”数据大海捞针”到”AI炼金术”
想要打造一个像 Nemotron-Nano-12B-v2-Base 这样聪明的 AI 模型,可不是煮杯咖啡那么简单。
它的训练过程分成了几个疯狂又硬核的步骤,简直像是在科技版的地狱厨房进修:
第一步:”暴力”预训练(数据大胃王挑战赛)
总结:预训练就是让AI在数据的海洋里疯狂”狗刨”,游出肌肉(参数)和脑力(理解能力)!
科技界的学霸大比拼:模型训练的奇幻冒险
1. DeepSeek-R1:从菜鸟到学霸的逆袭之路
DeepSeek-R1 这一家子的故事可精彩了——
2. Nemotron-Nano-12B-v2:数学和代码界的卷王
这位选手的训练方式简直堪比《舌尖上的数据》:
3. 技术的终极压缩大法:蒸馏+对齐=变身超级AI
想成为顶尖AI?光靠数据不够,还得训练到极致!
结论:强者各有千秋,但都有同一个目标——成为最完美的AI!

Minitron策略:让巨人模型穿上”瘦身衣”
当研究人员终于完成了模型的”对齐”(就像给一只暴躁的AI宠物做了心理辅导),就该用Minitron策略开始给它”疯狂减肥”了。这个120B参数的大家伙——比一个装满数据的硬盘还重——要被压缩成”身材苗条”的9B版本,而效果还得保持在”智商不下线”的状态。
Minitron策略:NVIDIA的”瘦身大师”
Minitron可不是什么机械战警,而是NVIDIA研发的一套模型压缩”组合拳”,主要包括两招:
终极目标:让大规模AI”人人吃得消”
NVIDIA的目标很明确:让这个9B版本不仅能跑得快、吃得少(单张A10G搞定),还能保持128k上下文的理解能力——就像把一个整天嚷嚷着要高端服务器的AI大佬,调教成一台家用电脑都能跑的小可爱。
这波压缩成功后,AI推理的成本能大幅降低,说不定未来连你家的”古董显卡”都能跑大模型了(当然,最好是不要抱太大希望)。
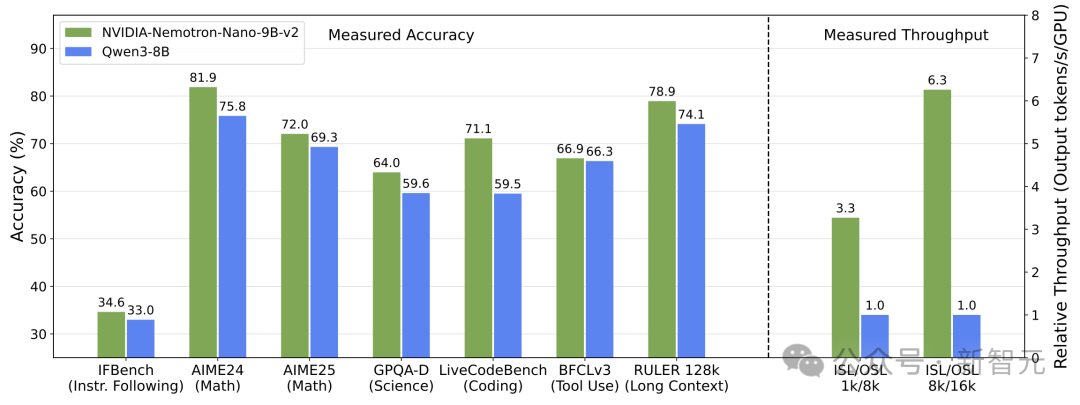
性能碾压,精度与速度全都要!
震惊!这匹AI界的”黑马”能文能武、气死同行!
赛道初体验:谁说”遛”不是正经比赛?
来,先看看Nemotron-Nano-9B-v2这份简历:
性能爆表:快得像偷偷装了火箭推进器
江湖传言:开源界的”卷王”诞生了?

全面开源
英伟达的开源大招:让AI吃得更饱的”自助餐”
英伟达这次可不是随便发几个小模型应付差事了,而是直接把整个”厨房”都对外开放了——128K上下文长度的模型全家桶外加6.6万亿Token的数据集,堪称一场AI界的”米其林自助餐”。
三大主菜:128K超长记忆力
超豪华配菜:6.6万亿Token的AI营养餐
英伟达这次可没说”训练数据不给”,直接大方地甩出了一个巨型数据集包,涵盖网页爬取、数学、代码、SFT和多语言问答,简直是AI界的”满汉全席”,下面是亮点菜谱:
Nemotron-CC-v2
Nemotron-CC-Math-v1
Nemotron-Pretraining-Code-v1
Nemotron-Pretraining-SFT-v1
Nemotron-Pretraining-Dataset-sample
开源界变天?Meta跑路,英伟达默默填坑
Meta(Facebook的母公司)以前是开源的排头兵,结果Llama逐渐变成”Llama Plus(付费版)”,开源精神悄悄缩水。相比之下,国内的AI厂商还坚持开源,OpenAI虽然也开源了两个模型,但噱头大于实质。
而英伟达这位”芯片界的搬运工”居然悄咪咪地开源了一大堆好东西,甚至还公开了预训练数据,简直就是AI界的”雷锋”。如果你好奇这群128K长记忆模型有多猛,可以去英伟达的体验站玩玩——除了它家的模型,还能找到不少其他人的开源成果。
总之,AI圈的免费午餐越来越丰盛了,这次英伟达确实没让人失望!
NVIDIA 推出 Nemotron-Nano-2:你的下一个AI模型,可能比你的午餐还小
如果你还在为那些动辄上百亿参数的AI模型头疼,那么NVIDIA的最新研究可能会让你笑出声来。他们刚刚推出了 Nemotron-Nano-2,一款小巧、高效、且性能惊人的AI模型,目标直指高效推理(而不是占满你的内存)。
——不是越大越好,而是越聪明越好!
所以,如果你的AI项目还在担心计算资源爆炸,说不定这个 Nano-2 就是你的新希望。当然了,它仍然姓“NVIDIA”,所以性能这块,你懂的。
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。