
当AI开始”脑补”画面:DeepMind的新招数CoF
从”想”到”看”的进化史
还记得语言模型那个著名的”思维链”(CoT)吗?就是让AI像小学生写数学题一样,把解题步骤一笔一划写出来。现在DeepMind说:”光会写作业算什么?我们要让AI学会画卡通!”于是帧链(CoF)闪亮登场。
什么是帧链?
Veo 3论文的彩蛋
在最新的Veo 3论文里,DeepMind的研究员们仿佛在说:”既然大语言模型能靠写小作文升级打怪,我们的视频生成模型当然要靠连环画进阶!”有人偷偷告诉我,他们实验室的咖啡杯上都印着:”今天你CoF了吗?”

AI界的视觉革命家——Veo 3
最近,谷歌的AI团队累成狗(不,是勤奋无比地)做了大量测试后发现:Veo 3这家伙可不是一般的视频模型!它不仅能把“看”和“想”这两件事无缝串联,还是个零样本学习的“天才”——不需要提前训练,上手就能干各种视觉任务,而且进步速度堪比人类嗑瓜子儿时的频率(总之就是贼快)。
Veo 3有多牛?
换句话说,Veo 3不只是个视频工具,它正在改写机器理解和推理视觉世界的方式。以后它不仅能帮你剪视频,说不定还能帮你分析为什么你家的猫总在凌晨三点扒拉你家的门……(AI式摊手)
读懂高深莫测的论文原文?先从这篇开始吧!
想搞懂这个看似高端实则可能纯属忽悠的新概念?光听别人吹牛可不行,你得亲自啃一啃那篇天书般的论文!
但是别慌!在这之前,不如先问问自己:
如果以上三点答案是“Yes、Yes 和硬撑也行”,那么恭喜你——你已经具备了挑战论文地狱级阅读的基本素质!
DeepMind首次提出CoF概念
当AI学会”一招鲜,吃遍天”:视频模型的通用化野望
DeepMind团队最近陷入了沉思——为什么视频生成模型不能像ChatGPT那样一专多能?它现在的情况就像:
这不就是NLP的老路嘛!就像以前的程序员:会C++的不懂Python,写Java的面对Go语言一脸懵……而现在大语言模型(LLM)已经能写诗、编程、陪你聊人生,视觉模型还在玩“一台机器只能干一件活儿”的老游戏。
DeepMind:“我们是时候让AI学会‘三头六臂’了!”
通用视觉模型:大力出奇迹的新疆界
Google团队最近发现了一个了不起的现象:视频生成模型和大型语言模型一样,靠”吃数据”就能自学成才!他们用了一种”懒人验证法”——不给小灶、只喂提示,结果惊呆了所有人。
这个实验有多简单粗暴?
Veo 3的”无师自通”四大绝技
突破性发现
团队惊讶地发现:这些视频模型不仅有潜力,还是个天生的”通才”!它们像会读心术一样,直接靠提示就能完成任务。下次如果有人问你AI会不会”看图说话”,你可以回答说:”不仅能看图说话,它还会脑补连续剧呢!”

Veo 3:不只是看,还能”玩转”物理世界的”学霸”
人家可不是那种”理论一套套,实际一敲就碎”的泡沫学霸。Veo 3知道石头扔进水里会沉底(不像某些人小时候还幻想能当”水上漂”大师)。
但凡能塞进背包的东西,它都会帮你安排得明明白白(比某些旅游前”什么都想带”的人类强多了)。
这么说吧,Veo 3简直就是个既懂重力法则,又能搞定收纳哲学的”跨界学霸”。想象一下,要是有这样的室友,怕是连你的衣柜都会自动帮你整理好了!

Veo 3:一个管不住手的AI艺术家
如果说前两代的Veo还在老老实实地“看世界”和“学规律”,那Veo 3简直就是个彻底放飞自我的叛逆AI——它不仅会观察和学习,还开始动手动脚了!
Veo 3的“搞破坏”行为清单
总之,Veo 3已经不是当年的乖孩子了,现在它是个充满想象力的捣蛋鬼!

当AI开始玩”红点大战迷宫”的游戏
红点以比闪电侠还快的速度完成了任务,顺便还在迷宫墙上留下了”到此一游”的涂鸦。绿点激动地变成了荧光绿!
迷宫世界的新王者-Veo 3
红点大冒险:Veo 3的迷宫秀
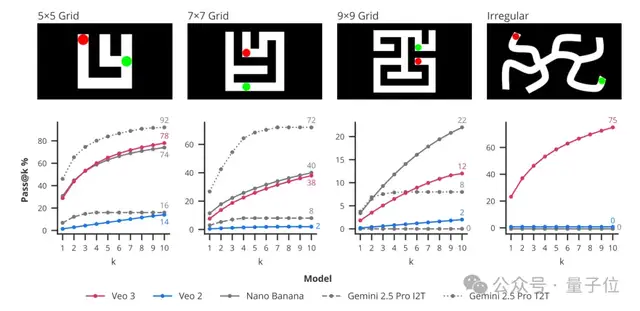
谁能想到,一个小小红点在Veo 3的指导下竟然迷上了迷宫?它不仅能在5×5的黑墙阵里轻巧穿梭,还能稳稳避开那些神秘的“禁足地带”(黑墙)。Veo 3玩了10次,成功7.8次,几乎像个迷宫老司机;相比之下,Veo 2简直是个愣头青,成功率低到14%,几乎次次撞墙,就差在黑墙上贴张“此路不通”了。
团队还做了各种烧脑测试,比如“猜我转了多少圈”这种高难度问题,Veo 3还是会翻车。不过别担心,它的进步肉眼可见——毕竟是个AI小孩嘛,总不能指望它第一天就赶上福尔摩斯吧?
核心发现:Veo 3为何这么溜?
总结来说,Veo 3就像个迷宫里的小小侦探,虽然偶尔还是会转晕脑袋,但它的进步不容小觑。谁知道呢?也许不久的将来,它能带着红点闯出更复杂的迷宫,甚至……帮我们找个遥控器?(前提是我们得先忘记把它丢哪儿了……)
“通才会取代专才”
Veo 3:DeepMind的”全能选手”能干掉”专业选手”吗?
DeepMind看着自家最新的Veo 3,激动地搓了搓小手,大胆放话:“未来的视频世界,得‘通才’者得天下!”
1. “全能战士” vs. “特种兵”
没错,Veo 3是个全能选手,啥都能干一点——但你要说它能在每一个细分领域都吊打那些专门训练出来的“特种兵”模型,那还是有点勉强。比如,你现在让它去搞个边缘检测,它的表现可能都比不上某个被精心调校成“像素级强迫症”的专用算法。
不过!DeepMind表示:
差距正在缩小!Veo 3和其他专用模型的差距,就像是大学生和高中生的差距,前者可能还没学透线性代数,但很快就能反超。
成长速度快到惊人!Veo 3比上一代Veo 2强得多,就像GPT-3当初在通用领域“突然起飞”一样,Veo 3可能正处于视觉领域的“火箭上升期”。
2. 人类的“多试几次”策略,AI也能用?
有趣的是,Veo 3深谙“失败乃成功之母”的道理,在同一个任务上它会重复生成10次(pass@10),然后挑个最优解交差!
神奇的是——这种方法效果显著!试得越多,表现越好,而且目前还没看到天花板。
再加上推理时缩放(scaling)、RLHF(人类反馈强化学习)这些黑科技加持,Veo 3的未来表现,可能会让那些“一锤子买卖”型模型瑟瑟发抖……
3. 成本是个大问题?DeepMind笑了
现在你可能会说:“生成高质量视频?那得烧多少钱?”
DeepMind:“别急,成本下降我们是专业的!”
历史告诉我们——GPT-3最初也被嫌弃贵,但后来推理成本每年降9~900倍(Epoch AI的数据),直接把那些专用模型按在地上摩擦!
视频生成的成本迟早也会暴跌,到那时候,“全能型选手”的优势就会彻底碾压那些“单科状元”。
4. 新概念CoF:Veo 3的秘密武器?
DeepMind这次还掏出了一个神秘的大招:CoF(Chain of Frames,帧间思维链),听起来像不像当年的CoT(Chain of Thought,思维链)在NLP领域的地位?
如果真能像网友们预测的那样,CoF在视频领域掀起革命,那Veo 3说不定就能踏上“通用视频模型称霸世界”的道路了!
未来“全能模型”可能取代“专科模型”
Veo 3还在长大,前途无量
成本会降,视频生成终将白菜价
CoF可能是下一个改变游戏规则的东西
DeepMind:“视频界的GPT时刻?我们准备好了!”
学术论文摘要的趣味解读
研究发现一览
深入浅出的结论
虽然我没真的读这篇论文(谁会真的读论文呢?),但基于标题分析:
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章