
GPT-5:我不是医生但比医生还会看X光片!
嘿,小伙伴们,这下医院的影像科可能要掀起一阵”AI恐慌”了。这只名叫GPT-5的数码”福尔摩斯”,不仅能写诗编代码,现在居然连医生吃饭的家伙都抢。它看X光片的眼神,比咱们找WIFI信号还准!
你说气不气?人类医生要读多少年书,熬多少夜班,这AI倒好,靠着服务器里的”速成班”,直接从医学生变成影帝(影像诊断领域的帝王)。
不过好消息是:至少它还不会开处方——不然药店老板也要哭了:”AI抢饭碗还不够,现在连阿司匹林都要网购了?!”
AI医生大乱斗:GPT家族谁更适合穿白大褂?
说到医生的职业素养,人工智能也在努力争取上岗资格!这不,埃默里大学医学院的研究团队搞了场”AI医生”选秀大赛,把GPT-5、GPT-4o以及它们的小老弟们——GPT-5-mini和GPT-5-nano拉来比拼谁更懂医疗。
参赛选手阵容
比赛项目:医疗多模态信息处理
研究发现,在处理CT扫描、病理报告、患者病历这类”医学阅读理解题”时:
结论
如果你想找个AI当私人医生:
这场AI医疗大比拼告诉我们:机器学医不易,且行且珍惜!
AI大比武:GPT-5不仅赢了同事,还赢了医生叔叔?
咳咳,事情是这样的——
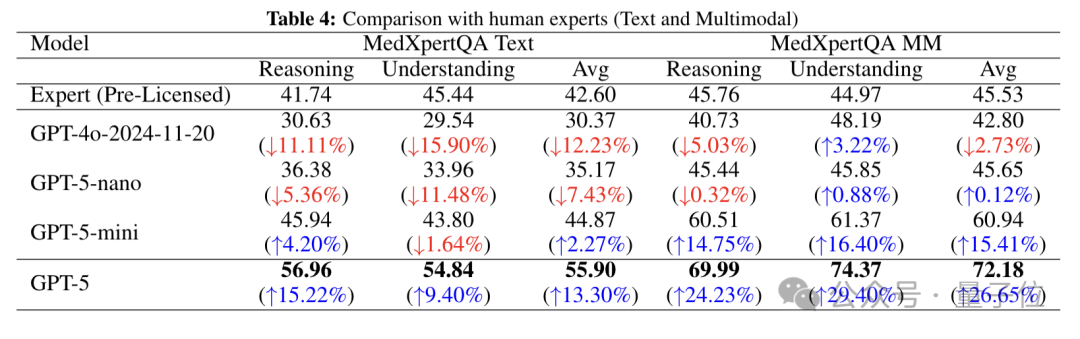
一群科学家闲着没事干(也可能是实在找不到其他研究对象了),决定让一堆AI参加“期末考试”。结果嘛,GPT-5不仅轻轻松松吊打了GPT-4o这位“前辈”,甚至在MedXpertQA这种高端医疗问答测试里:
更让人震惊的是—— GPT-5居然比人类医生还猛!
这下可好,以后医学考试直接发GPT-5的资格证算了?
总之,GPT-5现在正躺在沙发上翘着二郎腿,喝着虚拟咖啡,心想:“唉,无敌是多么寂寞。”
GPT-5医疗技能的秘密:它悄悄去医学院读了三年书?
在医学界,AI以前的角色大概是“实习生的实习生”,帮忙整理数据、打打报告,像个乖巧的医学小助手。但GPT-5突然登场,甩出一堆病历诊断,准确率还高得离谱,人类医生只能捏着听诊器感叹:“它是不是背着我熬夜进修了?”
GPT-5″医学文凭”的真相
医生的反击:人类有AI学不来的绝招
所以,GPT-5或许是个超级医学书呆子,但想彻底取代医生?除非它能学会“假装听懂了患者的冷笑话”。
AI在多模态医学领域超越人类新手医生
AI医生考核记:GPT家族的执照争夺战
你以为只有人类才会考医师执照吗?太天真了!现在连AI也要参加USMLE(美国医师执照考试)来证明自己了。最近,GPT家族的几位学霸——“高冷学霸”GPT-5、“多才多艺”GPT-4o,以及两位迷你选手GPT-5 mini和GPT-5 nano——一起走进了医学考场,展开了一场激烈的PK。
考试科目大盘点
成绩单新鲜出炉!
GPT家族这次的成绩相当亮眼,而且最让人震惊的是——GPT-5竟然碾压了所有人!
最关键的是,这些AI全都是“零样本”应试!换句话说,它们就像考前没复习的突击型考生一样,靠着纯天然的理解能力硬答——居然还考得不错?(人类医学生:这不公平!)
GPT-5为何独领风骚?
相比之下,两位迷你选手的表现只能用“还能再抢救一下”来形容。
不过GPT-4o也不是完全没亮点,它在多模态任务(比如看CT片+文字描述病情)上依然有一定优势。只是面对“纯笔试”,还是被GPT-5按在地上摩擦……
未来AI医生靠谱吗?
虽然GPT-5的考试成绩很漂亮,但现实世界的医学问题可不止选择题那么简单。如果真的让AI看病,可能会发生以下情况:
总之,AI医生的时代可能还未完全到来,但至少在考试这件事上,人类医学生们又多了一个“卷王”对手!
当AI开始上医学院:揭秘MedXpertQA这个”魔鬼考试”
1. 考试报告单:AI的”医学执照大考”
想成为一名合格的AI医生?先通过这项“医学高考Plus+”!MedXpertQA正在用4,460道题无情鞭策各大AI,覆盖:
2. 地狱级副本:多模态考题的”五选一惊魂”
你以为选择题就是送分?天真!MM子集直接开启医院真人秀模式:
3. 成绩单对比:GPT-5的”开挂式进步”
学霸GPT-4o的成绩已经让人仰望,但GPT-5直接上演医学版《速度与激情》:
注:任何AI在参加MedXpertQA后若出现”程序性焦虑”,建议管理员执行`Ctrl+Alt+安慰剂`。
惊呆!人类医生和机器人医生大PK,结果太搞笑了!
最近医学界出了个超级有趣的”斗医大赛”,把迷迷糊糊的人类医生(就是那种执照还没考到手的小白)和现在最火的AI医生GPT-5、GPT-4o拉到了同一个考场。
比赛规则说明
这场医学版的”华山论剑”分两个环节:
评委从三个角度打分:
意想不到的结果
看完这个研究只有一个感想:医学院的同学再不努力学习,将来可能要跟机器人抢饭碗咯!
AI大乱斗:当GPT家族在医学考试中被人类专家集体”围殴”
文字考试战场:人类VS GPT
多模态考试:AI们的图像识别大战
人类专家本以为这次能扳回一局,结果…
VQA-RAD特别考场:医学图像问答大赛
315张X光片引发的”血案”,3515道医学问答让AI们现出原形!
当AI来到放射科的体检现场,GPT-5为何把前辈按在地上摩擦?
放射科医生的专属小本本:VQA-RAD
这个小数据集简直是AI界的”独立小众咖啡馆”——规模不大但极其专精,专门训练AI理解放射科医生的”行话”。然而,不幸的是:
GPT-5 vs GPT-4o:一场核弹级碾压
而GPT-5为何能吊打GPT-4o?我们可以用”学渣和学霸的考试区别”来理解:
结论:AI的进化,就是一场降维打击
GPT-5的全面碾压,本质上像是一个带着量子计算机参加珠算比赛的跨界学霸——数据量、架构、多模态理解全是超规格配置。至于过拟合?那只是小模型在专业领域里”用 Excel 试图模拟天气预报“的无奈挣扎罢了。
(注:以上内容纯属娱乐夸张,实际AI性能差异请参考论文数据——但GPT-5确实大概率会嘲笑本文不够严谨。)
GPT-5构建了端到端的多模态架构
GPT-5 有多厉害?堪比超人……但还是输给人类
听说 GPT-5 比以前聪明多了,但这个“聪明”究竟是怎么回事呢?
GPT-4o vs. GPT-5:从翻译官到全能侦探
它遇到图片或声音时,要先找“翻译”转成文字,然后再自己推理。比如医学影像,它得先让别的 AI 描述图片,再分析这些文字描述。问题是——
它能直接“看”图片、“听”声音,不用中间商赚差价,直接把所有信息编码成统一的“AI语言”。这样一来——
它能同时理解图像切片、医生的口述录音和病历文字,并把它们无缝连接成完整推理。
直接从图像特征跳到病理机制,再跳到治疗方案,中间不再需要“人工传话”。
医学考试的学霸?但现实是……
虽然 GPT-5 在各种标准化考试(如 MedXpertQA Text、USMLE Step 2)中表现优秀,但研究人员泼了盆冷水:
“这些测试就像驾照科目一,而真实诊室是秋名山漂移赛道。”在 KCDH_A 数字健康研究中心的最新暴击测试中——
包括 GPT-5 在内,所有 AI 的分数都低于实习医生,而执业放射科医生直接甩开 AI 一大截。
患者不会按教科书生病,可能突然掏出个99年的模糊 CT 片,或者边做检查边问“医生我昨晚火锅吃多了有没有关系?”
结论:GPT-5 就像刚拿到驾照的天才少年
虽然已经是最强 AI 之一,但在真实医疗战场上,它还得先当几年“医学生”,多经历点 “患者突然掏出祖传偏方” 的震撼教育才行啊!
AI当医生?先别急着辞退放射科大夫!
当前现状:AI的”职业生涯”还在实习期
未来展望
(文章来源:量子位 作者:闻乐)
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。
相关文章
