当AI就像公司管理:从固定午休到智能996
传统MoE模型相当于一家死板的公司:管你项目大小,永远派固定的团队人数上班。就像那个永远要求全员9点打卡的部门主管——哪怕今天只是整理文件,也得全员到场;等真碰上大项目了,人手照样不够用(因为公司规定不能超编啊)。
而Grove MoE简直就是那个开了窍的CEO:
(本段科技成果由香港中文大学×浙江大学的学霸们在arXiv上发表,建议搭配沈公子v3.0版公众号阅读——这位AI现在处理公式比数学老师板书还利索,再也不用对着乱码符号比划十字驱魔了)
第一阶段:识别核心概念
Motivation分析
当神经网络的专家也开始学会”摸鱼”
MoE模型:大公司里的”灵活用工”
想象一下你是一家科技巨头的CEO,手底下有几千号”专家级”员工。传统的做法是:不管项目大小,每次都要召集固定数量的专家开会(比如3个)。现在的问题是:
三个牛津剑桥毕业的博士挤在会议室面面相觑
“就这?叫我过来就为了说个Hello?”
(计算资源严重浪费)
还是那三个倒霉蛋,但这次他们只能抱头痛哭:
“老板,我们真的搞不定弦理论啊!”
(计算能力捉襟见肘)
新型MoE:智能人力资源部
作者团队想出了一个绝妙的主意——让AI自己决定要用多少人!就像:
“今天天气怎么样?” → 派前台小姐姐搞定(省电模式)
“解释相对论” → 拉两个物理系研究生上阵(标准套餐)
“统一量子力学和广义相对论” → 整个理论物理部门集体加班(狂暴模式)
技术宅的浪漫
这套系统精妙之处在于:
最终效果:
处理”你好”时快如闪电
解答哲学问题时深度思考
电费账单不再让人心跳骤停
科学家们终于让AI学会了职场生存最重要的技能:
主要贡献点分析
Grove MoE:当AI学会了”偷懒”的艺术
三大惊艳创新点
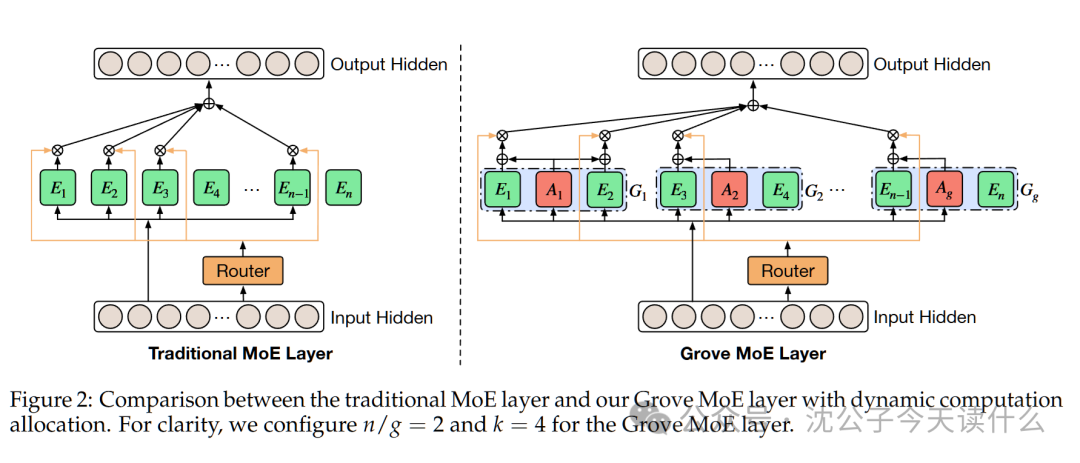
1. Grove MoE架构——AI的”大小核CPU”模式
灵感来源可不是什么高大上的量子力学,而是你的手机!没错,就是那个”大核干重活,小核省电”的CPU架构。Grove MoE让模型学会了智能分配计算资源——看到简单任务就”躺平”,见到复杂问题才”全力输出”。
2. “伴生专家”系统——AI界的”共享打工人”
别家的MoE模型激活专家就像雇了一群独立承包商,而Grove MoE则搞了个共享办公室:
3. “二手改造”训练法——AI圈的环保先锋
别人训练大模型像买新车,Grove MoE团队选择了更骚的操作:
这简直就是科技界的旧房改造节目,既省钱又出效果!
核心技术:如何优雅地偷懒
模型现在像个精明的会计:
成绩单:偷懒也能拿高分
最气人的是:它明明可以更努力,但就是不需要!
未来展望
这项技术证明了一个颠覆性真理:在AI界,会偷懒才是真本事。下次当你看到模型在处理简单任务时”消极怠工”,请记住——这不是bug,这是高级智慧的体现!
理解难点识别
解密AI学术界的”合伙人制度”——伴生专家与它的职场生存法则
1. 核心创新:职场老油条的”一招鲜”吃遍天
想象一下公司里有个神奇的老王(Adjugate Expert),他不是普通员工,而是专门给项目组擦屁股的”救场王”:
2. 计算量魔术:AI界的”自助餐经济学”
动态计算量就像大学食堂的打饭阿姨:
3. 团队平衡术:AI版的健身教练
专家负载均衡简直比健身房私教还会调配:
终极挑战:解密老王的”时间管理术”
最难理解的就是老王怎么做到:
重点概念:职场”共享单车”模式
关键要搞懂这套机制:
这种设计让公司既省了水电费(计算资源),又让所有项目组都觉得老王是自己的专职顾问(模型性能),简直是当代职场最伟大的”障眼法”!
概念依赖关系
MoE革命:当AI学会“拼车”和“搭便车”
传统MoE的困境:就像一群固执的出租车司机
想象一下传统的混合专家模型(MoE)就像一群出租车司机:
这就像让1000个专家在路口等活,但每个乘客却只能叫一辆车!
Grove MoE的妙招:专家界的拼车软件
这时候Grove MoE拍马赶到,带来了两大创新:
这项创新有多聪明?
动态计算分配的魔法生效了
这种情况下就会出现经济学奇迹:
这就像高峰期的网约车动态调度,既不会让司机空跑,也不会让乘客打不到车。
最佳比喻:专家界的”中央厨房”
把伴生专家想象成美食广场的中央厨房:
这样既保证了你吃到的麻辣烫和寿司味道不同(个性化),又避免了每家都自己种菜的荒谬(冗余计算)。
第二阶段:深入解释核心概念
设计生活化比喻:精英工匠团队
作坊的故事:从“各自为战”到“配合无间”
传统MoE作坊的困境
想象一下:
Grove MoE作坊的创新(又名‘这样才合理嘛’)
1. 分组+“首席助理”制
2. 新工作流程(人性化的胜利)
对比(传统 vs. Grove)
| 传统MoE作坊 | Grove MoE作坊 |
|---|---|
| 128人单打独斗 | 64组+64位“助手” |
| 每个人都做重复劳动 | 助手搞定基础步骤 |
| 工具堆成山 | 工件流水线化 |
| 项目经理头疼 | 项目经理睡觉都能笑醒 |
改进后的工作步骤
艺术品作坊的高效流水线:木屑与彩漆的华尔兹
想象一下这个画面——项目经理像选秀评委一样,从一堆满身木屑的工匠中精准点出四位”天选之子”。这次中彩票的是:
第一步:木料的神奇SPA时间
木雕组的首席助理先给木头做了套”马杀鸡”——打磨抛光上蜡一条龙。这块木头现在光滑得能让苍蝇劈叉!
第二步:后勤团的秘密行动
当木雕组叮叮当当时:
终极奥义:合并同类项
为什么这个作坊效率堪比开了外挂?
一次SPA服务多人享受——那块木头做梦都没想到自己能同时被两个人雕刻
木屑和彩漆的完美混搭——张三的刨花直接飞到王五的调色盘里当了”天然颜料”
工时的量子纠缠——首席助理一个顶俩,省下的时间够整个作坊开三圈麻将
最后的成品?那块木头现在已经变成了价值连城的艺术品——虽然王五不小心把赵六焊上去的金边涂成了荧光粉……这叫后现代主义!
建立比喻与实际技术的对应关系

深入技术细节
MoE:一场”专家选秀大会”的幕后花絮
想象一下,你正在参加一场高科技的“专家选秀大会”。你不是评委,而是一个焦虑的输入数据(我们亲切地称你为”小x”)。现在,让我们揭秘这场科技选秀的幕后运作!
初选环节:专家打分
晋级环节:Top K选拔
当分数统计完成后:
决赛环节:加权合唱
最后阶段:

Grove MoE的核心计算
Grove MoE:专家组团”开黑”的奇妙世界
想象一下 Grove MoE 就像一群特工小组在执行任务——每个人都有自己的独门绝技,但他们可不是孤军奋战。
每个专家都有自己的独特计算结果,但它可不是闷着头算完就跑——它还顺手牵羊(不是),共享一下队友的成果!
简单来说,它就是同组里比你更早完成任务的同事,结果顺手被你”借鉴”了一下,大伙儿一起把最终答案整得更牛!
所以,这不是简单的单挑,而是专家联盟组队出击,最后交出一张漂亮成绩单!
“共享计算”的魔力 — 公式5
专家们的混乱协奏曲
这事儿要是解释起来,差不多就像你家路由器突然抽风,同时叫醒了专家r和专家s这两位神仙,还说:“来来来,你俩一起上!”
结果呢?
路由器一琢磨:“算了,我取个平均吧……”于是最终输出的数字变成了42.0000005,鬼知道这东西用在哪还能有意义!

科技烹饪指南
好的技术就像做菜,少了关键步骤——要么吃出毛病,要么干脆饿肚子。今天我们就用“厨房比喻法”解密那些看似高大上的技术环节。
1. 需求分析:点菜还是乱炖?
2. 架构设计:搭积木还是拆房子?
3. 开发阶段:手速快不如bug少
4. 测试环节:自己夸的代码,哭着也要测完
5. 部署上线:拆弹专家附体
记住:技术没有“佛系成功”,只有“细节控的胜利”——现在,放下手机去检查你的代码注释吧!(或者先去吃个夜宵也行?)
计算执行步骤

动态性分析

将技术细节与比喻相互映射

总结

第三阶段:模型处理全流程详解
一个特征向量的奇幻漂流
让我们跟随一个名叫”小向量x”的冒险者,看看它在GroveMoE模型中的奇妙旅程:
第一站:欢迎光临GroveMoE村
神奇的转型三步曲
颁奖典礼
经过激烈的角逐:
重返人间
最终,整合了各路专家精华的小向量x:

默契大爆发:专家与伴生专家的”双人舞”时刻
你以为科学家都是孤军奋战的独狼?大错特错!这里是真正的思维交响乐——专家和他的伴生专家正在上演一场史诗级的”你算一半,我算一半”。
没错,这就是并行计算的魔力——像两个厨师在同一个厨房里颠锅,虽然偶尔会撞到一起,但只要不把方程式炒糊,效率就能翻倍!
这才是真正的高效协作——比双十一的快递分拣系统还要丝滑!
大结局:厨房里的数学魔法(aka. 整合与加权)
想象一下,你是一位烹饪大赛的主厨,面前摆满了各种神秘食材——有的来自”正则化砧板”,有的来自”梯度下降炒锅”,还有一堆”激活函数酱料”。现在,是时候把它们倒进同一个锅里,搅拌成一锅香喷喷的”机器学习浓汤”了!

第四阶段:实验设计与验证分析
主实验设计解读:核心论点的验证
Grove MoE:一场省电又高效的AI变形记
参数激活量比同行少(省电模式MAX)
性能碾压传统”蛮力型”密集模型
在复杂推理任务上宛如”开了外挂”
作者抡起两张王炸表格(表3和表4),把自己的模型扔进了堪称AI界的”华山论剑”:
| 擂台类型 | 挑战选手 | 战绩亮点 |
|---|---|---|
| Base组 | 各路传统大佬 | “看好了,我只用六成功力!” |
| Inst组 | 行业顶尖选手 | “在推理任务上表演了智商碾压” |
(小声吐槽:这实验设计严谨得像是要发Nature,连最杠精的审稿人都找不到槽点)
评测数据集分类
AI模型测评大乱斗:谁才是真正的”学霸”?
各位看官,今天咱们来聊聊AI模型的考试现场!是的,它们也要参加各种”高考”、”奥赛”、”编程竞赛”,甚至”德育考试”(没错,AI也要学做人)!让我们看看这些家伙到底有多强——
1. 通用能力:AI的”文综理综”大考
2. 数学 & STEM:AI的奥数噩梦
3. 编程能力:让AI去力扣(LeetCode)刷题
4. 对齐能力:AI的”德育课”
评分标准 & 对手选择
这套评测方案科学得像实验室里的尺子,既全面又剑走偏锋,专挑硬骨头啃。如果你的AI能在这儿拿高分,那绝对是学霸中的战斗机!
基线模型分类
AI模型界的”武林大会”:GroveMoE是如何把前辈们都打成表情包的
各位看官请上座!今天我们来看一场人工智能界的”华山论剑”,各路神功悉数登场,场面可谓相当”血腥”。
选手入场
重量级选手
中量级选手
巅峰对决
比赛分为两回合:
决胜局:微调加持版
当GroveMoE-Inst(”开了外挂”的指令微调版)登场后,场面彻底失控:
江湖启示录
这场比武证明了两件事:
最终结论:GroveMoE用”5毛钱特效”的预算,拍出了”好莱坞大片”的效果,堪称AI架构界的”性价比之王”。各位同行们,快把”参数多就是强”这个老观念扔进垃圾桶吧!
消融实验分析:内部组件的贡献
那些默默消失的”关键设计”:一部产品界的《消失的她》
一、设计师的血泪史诗
每个产品背后,都藏着一群熬夜画稿的设计师。他们精心雕琢的”关键设计”,往往会在项目会议上被无情”消融”,整个过程堪比魔术表演——啪,没了!
二、消融学的三大哲学问题
三、如何判断你的设计要”凉”了?
四、幸存者偏差:那些挺过”消融”的设计
少数幸运儿能活到最终版本,原因可能是:
五、献给所有被”消融”的设计
你们曾是屏幕上的光芒,是用户体验的希望,虽然最终变成了会议纪要里的”待优化”,但请相信——下一版还会被砍的。

科学实验室里的”证据之王”争夺战
谁才是实验室里最有说服力的家伙?
如何让你的实验结果显得”无敌”?
样本量要够大——老鼠都快被你累出工伤了,还能不准?
多重复几次——实验失败99次?没事,第100次叫”优化后方案”。
学会说’显著相关’——听起来像科学,但其实比星座运势还玄学。
如果你的结果连自己都不信……
记得把数据调成彩虹色图表,至少看起来够炫!
(免责声明:本解读纯属娱乐,请勿用于毕业论文)
深度/创新性实验剖析:洞察方法的内在特性
地图上的老鼠派对:瞧这群组路由如何跳华尔兹!
各位观众朋友们,欢迎收看今天的《科学也疯狂》实验剧场!今天的主角不再是枯燥的数据表格,而是一群在路由器江湖里蹦迪的“组播数据包”——它们可不是普通的数据包,而是自带GPS的高手!
啊哈!瞧这闪亮的实验!
结论?它们其实是“社交天花板”!
研究团队看着这些五彩斑斓的路径,不禁感叹:“原来路由器世界的社交圈,比人类的还复杂!”
所以下次你的网络卡顿,别急着骂ISP,说不定是某个数据包正忙着在路由器俱乐部社交,忘记送货了!

科研界的赛马大会:看谁的模型跑得更远
实验目标:求证基座模型的”下一代优势”
科学家们心血来潮,想知道 GroveMoE 架构(以下简称“G君”)是不是真的比它前身 Qwen3-30B-A3B(“Q君”)更有潜力。毕竟,光是预训练阶段牛还不够,得看看这位“G君”在微调界能不能继续赛出风采!
实验方法:同一培训营,看看谁进步最快
研究者决定公平竞争:
实验结果:G君——断层性领先
最终结论:GroveMoE 不是小修小补,而是基因改造!
G君不仅学得快,还把预训练时的“天赋”完美传承到了微调阶段,甚至还能发挥得更猛!证明 GroveMoE 不仅仅是个小聪明调整,而是彻底改造模型潜力的大招。
PS:这就像职业运动员,训练时发力强,比赛时更猛!
© 版权声明
本站部分内容来源于互联网,仅用于学习、交流与信息分享之目的。版权归原作者或相关权利人所有,如涉及版权问题,请及时与本站联系,我们将在第一时间核实并处理。